一、大模型行业发展现状及前沿技术观察
1.1 大模型行业发展现状
2022 年 11 月底,OpenAI 发布了人机对话模型 ChatGPT,在两个月不到的时间内其线上活跃用户规模超过 1 亿人,生成式大模型受到越来越广泛的关注,人工智能行业进入到以大模型为代表的快速发展阶段,巨量参数和智能涌现是这一轮人工智能变革的典型特征。微软、谷歌、Meta、亚马逊等全球科技巨头将大模型视为重要的发展机遇,在生成式大模型领域加速布局,积极投入且成果频频。我国的众多互联网厂商和人工智能企业也积极投身到大模型领域中,百度、讯飞、阿里、华为、腾讯、商汤等企业也在快速更迭自己的大模型,同时高校、科研院所也积极投身大模型产业,取得了显著成果。
1.1.1 国内外大模型发展情况
国外大模型起步相对较早,2021 年进入到快速发展期。2017 年 Transformer 模型的诞生可以被视为大模型行业的开端,谷歌、OpenAI、微软、英伟达等大型科技企业引领了早期的技术探索,在 2020-2021 年间逐步确立了大模型的整体技术路径,国外大模型行业开始加速发展。根据赛迪顾问数据,截止 2023 年 7 月底,国外大模型累计发布 138 个,其中美国发布 114 个,大模型数量大幅领先。从 2020 年起,更多国家的企业和科研单位逐步加入到大模型的研发中,韩国、日本、法国模型数量位列美国之后。国外已发布的大模型主要集中在自然语言和多模态两类,其中自然语言占比 68%,多模态占比 18%,其他类型大模型合计占比 14%。
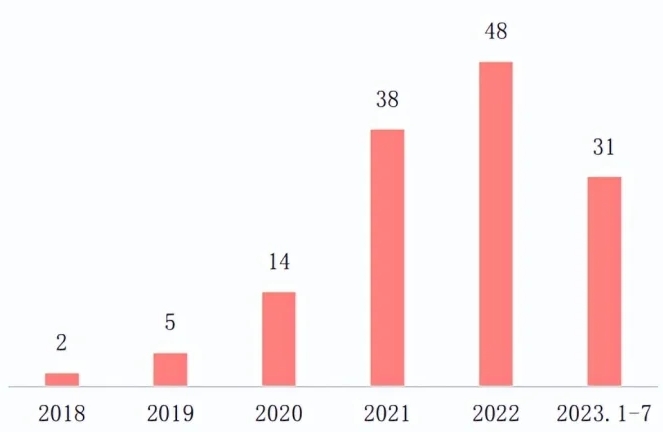
国外发布的大模型情况
在大模型产业领域,中国紧跟国际前沿。2021 年起,中国也开启了大模型的发布热潮,涌现出一批有代表性且具备影响力的大模型。受 ChatGPT 影响,国内大模型在 2023 年进入到高速发展阶段,一时间呈现“百模大战”局面。根据赛迪顾问, 截止 2023 年 7 月底,中国累计发布了 130 个大模型,其中 64 个大模型是在 2023 年年内发布。国内大模型技术分布基本与海外一致,65%的大模型集中在自然语言领域,22%的大模型集中在多模态领域。
1.1.2 国外大模型行业发展现状
(1)OpenAI:模型性能一骑绝尘,引领大模型行业发展趋势
2022 年底 ChatGPT 引爆社交网络,人工智能行业进入到以大模型为主的快速发展阶段。OpenAI 在 GPT-3.5 版本的基础上,通过 3 个步骤实现基于人类反馈的强化学习微调(RLHF),得到人机对话模型 ChatGPT。通过与人类答案的对齐过程,显著提升了大模型的人机对话体验。 GPT-4 具备卓越的文本处理能力,初步融合多模态能力,能力再度升级。2023 年 3 月 15 日,OpenAI 发布多模态预训练大模型 GPT-4,相较于过去的 GPT 系列模型,提升包括几个方面,GPT-4 相较于 ChatGPT 有更强 的高级推理能力,相较于过去的 GPT 系列模型,GPT-4 在更多应用领域成为专家,包括为机器学习模型评判标准和为人类设计的专业测试,从“百科全书”逐步成为文理通吃的“专家”。 GPT-4 在可控性和真实性方面较 ChatGPT 有大幅提升。
2023 年 9 月 25 日,OpenAI 再度开放了带视觉能力的 GPT-4V,用户能够指导 GPT-4 分析用户提供的 图像。在输入 GPT-4V 支持格式方面,其支持处理图像、子图像、文本、场景文本和视觉指针(visual pointers) 等多种输入。此外,GPT-4V 还支持 LLMs 中支持的技术,包括指令跟随、思维链和上下文少样本学习等。 GPT-4V 在处理任意交错的多模态输入方面具有前所未有的能力,并且其功能的通用性共同使 GPT-4V 成 为强大的多模态系统。 11 月 7 日,OpenAI 首次开发者大会发布了最新模型 GPT-4 Turbo,其作为一个标准化的 AI Agent,初 步具备了规划和工具选择的能力,可以自动选择接入互联网、进行数据分析、图像生成等诸多功能,真正 进化为了统一智能体。除了标准化的 GPT-4 以外,定制版的 GPTs 可以为用户在日常生活、特定任务、工 作或家庭中提供帮助,用户无需编写代码就可以创建属于自己的定制化的智能助理,诸多定制化的 GPTs 的使用体验显著优于 GPT-4,GPTs 开启了一个全民定制个人智能助理的浪潮。OpenAI 同时还将推出 GPT store 和 Assistants API,不断打造 GPTs 开发者生态。
(2)Google:深度学习研究的引领者,AI 技术产业落地先行者
在上一轮深度学习的 AI 革命中,AI 逐步达到了与人类媲美、甚至超越人类(部分场景)的水平,逐步走 入大众视野,而 Google 和 Deepmind 是其中的的引领者。由 Google 和 Deepmind 提出的 Word2Vec、AlphaGo 等模型以及 sequence to sequence、深度强化学习等技术是上一轮 AI 革命乃至这一轮 AI 浪潮的开创性、奠基性 工作,推动着 AI 技术的成熟与发展。在这一轮预训练大模型的 AI 浪潮中,AI 展现出在更多具体场景中强大的 应用性能,逐步从学术研究走向商业化落地。 Google 在 2022 年 4 月推出了 PaLM 模型,其具有 5400 亿参数,基于 Transformer 的 Decoder 设计,PaLM 模型在多个下游任务中具有优异性能。5 月 11 日,Google 在最新一届 I/O 开发者大会上官宣大语言模型 PaLM 2,称其在部分任务上超越 GPT-4。PaLM 2 在超过 100 种语言的多语言文本上进行了训练,这使得它在语言理 解、生成和翻译上的能力更强,并且会更加擅长常识推理、数学逻辑分析。PaLM 2 在大量公开可用的源代码 数据集上进行了预训练,这意味着它擅长流行的编程语言,如 Python 和 JavaScript,但也可以用 Prolog,Fortran 和 Verilog 等语言生成专门的代码。
目前谷歌的聊天机器人 Bard 已经超过 25 个 AI 产品和功能,都由 PaLM 2 作为底层技术支持。具体的表现 之一是 Duet AI,一款类似于微软 365 Copilot 的产品、能够内嵌在各种办公软件中的 AI 助手。基于 PaLM 2, 谷歌还推出了两个专业领域大模型。一个是谷歌健康团队打造的 Med-PaLM 2。另一个专业大模型是面向网络安 全维护的 Sec-PaLM 2,它使用人工智能来帮助分析和解释潜在恶意脚本的行为,并在非常短的时间内检测哪些 脚本对个人和组织构成威胁。
(3)META:通过开源 LLaMa 等大模型,引领大模型开源生态
LLaMA:2023 年 2 月 25 日,Meta 官网公布了一个新的大型语言模型 LLaMA(Large Language Model Meta AI),从参数规模来看,Meta 提供有 70 亿、130 亿、330 亿和 650 亿四种参数规模的 LLaMA 模型,并用 20 种 语言进行训练。Meta 推出的 LLaMA 参数规模有 70 亿(7B)、130 亿(13B)、330 亿(33B)和 650 亿(65B) 四种。LLaMA-13B 在大多数基准测试中,参数仅为十分之一,但性能优于 OpenAI 的 GPT-3(175B),而且能 跑在单个 GPU 上。LLaMA-65B 与 DeepMind 700 亿参数的 Chinchilla-70B 和谷歌 5400 亿参数的 PaLM-540B 不 相上下。
LLaMA2:2023 年 7 月 19 日,Meta 发布了免费商用版开源大模型 LLaMA2,各个企业能够以相对低廉的 价格在该模型上开发应用,为客户提供自主的大模型。Meta 发布的 LLaMA 2 模型系列包含 70 亿、130 亿和 700 亿三种参数变体,训练数据采用了更新之后的混合数据,模型方面采用文本输入与文本输出,预训练模型 在2万亿token上进行训练,训练token总数相较于LLaMA 1增加了40%。LLaMA 2学术基准测试优于LLaMA1, 专业场景中能力进一步提升。公布的测评结果显示,LLaMA 2 在包括推理、编码、精通性和知识测试等方面均 优于相近训练参数下的 LLaMA 1。LLaMA 2 模型最大的变化除了性能提升,还体现在 B 端可以助力企业开发自 己的大模型,C 端可以丰富 AIGC 应用,改变了以往大模型由多家科技巨头垄断的格局,AI 应用实现加速落地。 目前,用户已经能够在 Azure 平台上微调和部署 7B、13B 和 70B 参数的 LLaMA 2 模型。
Meta 与微软达成合作,联手推动 AI 应用的商业化落地。Meta 正式开源了 LLaMA 2 版本,可免费用于商 业用途,微软宣布携手。最新版本的模型将在微软的 Azure 和 Windows 平台上线并开源,用户可以在云服务中 使用 Llama 2 作为基础模型,快速构建适用于自身业务的专用大模型。目前,用户已经能够在 Azure 平台上微 调和部署 7B、13B 和 70B 参数的 LLaMA 2 模型。未来,LLaMA 将进行优化,以在 Windows 上本地运行。
1.1.3 国内大模型发展现状
(1)百度
从 2010 年的百度搜索开始,百度成立了自然语言部门,初步研究互联网机器翻译技术,2013 年推出百度语音助手,2014 年推出智能搜索小度机器人,2017 年推出智能客服。在长期的布局和发展中,百度构建了完整的语言与知识技术布局,包括知识图谱、语言理解与生成技术,以及上述技术所支持的包含智能搜索、机器翻译、对话系统、智能写作、深度问答等在内的的应用系统。 2023 年 3 月 16 日,百度发布了生成式人工智能大模型“文心一言”。作为文心大模型家族的新成员,文心 一言在文心知识增强大模型 ERNIE 及对话大模型 PLATO 的基础上研发。文心一言包含六大核心技术模块,包括:1)有监督精调;2)基于人类反馈的强化学习;3)提示;4)知识增强;5)检索增强;6)对话增强,前三类技术在目前流行的对话大模型如 ChatGPT 中都有所应用,而后三类技术则是百度基于自身技术积累的再创新,它们共同构成了模型的技术基础。
2023 年 5 月,百度文心大模型 3.5 版本已内测可用,在基础模型升级、精调技术创新、知识点增强、逻辑 推理增强、插件机制等方面创新突破,取得效果和效率的提升。2023 年 8 月 31 日,文心一言率先向全社会全 面开放。9 月 13 日,百度发布文心一言插件生态平台“灵境矩阵”。文心一言面向全社会开放至百度世界 2023 大会召开期间,40 多天的时间,文心一言用户规模已经达到 4500 万,开发者 5.4 万,场景 4300 个,应用 825 个,插件超过 500 个。 2023 年 10 月 17 日,百度世界大会上正式发布文心大模型 4.0。与原有的 3.5 版本相比,具有以下优势:1) 更强的模型能力和图片生成能力。根据测试,文心大模型 4.0 版本在理解、生成、逻辑、记忆四大功能上都有 明显提升,具有显著优化的模型性能。2)支持接入丰富的 API 插件,可以实现撰写代码、润色文案、设计与绘 图等多种功能。
文心一言成为首个国内面向 C 端收费的大模型产品。文心一言专业版的分为单独订阅和联合会员两种收费模式。单独订阅模式下,会员月付 59.9 元,选择连续包月可以享受 49.9 元的优惠价格;该模式下会员可以使用文心一言大模型 3.5 和 4.0 两个版本,而非会员只可使用免费的文心大模型 3.5 版本。联合模式下,用户月付 99 元,可以同时具有单独订阅模式的全部功能,并获得文心一格白银会员资格,享受 AI 修图改图等功能。
(2)科大讯飞
随着大语言模型爆火网络,公司自主研发了对标 ChatGPT 的星火大模型。星火大模型是基于深度学习、 以中文为核心的自然语言大模型,在跨领域多任务上具备类人的理解和生成能力,可实现基于自然对话方式的 用户需求理解与任务执行。 公司大模型不断迭代进步,能力实现全方位提升。2022 年 12 月 15 日,科大讯飞启动了“1+N 认知智能大模型专项攻关”。2023 年 5 月 6 日,讯飞推出星火认知模型的 1.0 版本,七大核心能力发布,同时发布大模型评测体系。6 月 9 日,星火升级至 1.5 版本,突破开放式问答、多轮对话能力和数学能力;8 月发布 2.0 版本,实 现多模态能力,同时代码能力显著提升。
星火 3.0 全面对标 ChatGPT。10 月 24 日,星火推出 3.0 版本,在语义理解、时效把握、代码生成能力等 基础功能上都有很大提升;在时空感知能力上表现突出;专业性能力基本无实时性错误,尤其医疗能力水平,可以给出适时的诊疗提醒。全面对标 chatGPT,中文能力客观测评超过 ChatGPT,英文能力对标 ChatGPT48 项 任务结果相当。根据国务院发展研究中心经济研究院测评报,星火大模型 3.0 综合能力达到国际一流水平,在 医疗、法律、教育行业表现突出。讯飞同时发布十二个行业大模型,涵盖金融、汽车交互、运营商、工业、传 媒、法律、政务、科技文献、住建、物业、文旅、水利十二个领域。讯飞正式启动对标 GPT-4 的大模型训练, 2024 年上半年对标 GPT-4。
(3)智谱
智谱 AI 致力于打造新一代认知智能大模型,专注于做大模型的中国创新,通过认知大模型链接物理世界的亿级用户。基于完整的模型生态和全流程技术支持,智谱 AI 一方面重视研发超大规模训练模型,并基于此推出对话模型 chatGLM;另一方面践行 Model as a Service(MaaS)的市场理念,推出大模型 MaaS 开放平台。 2023 年 3 月 14 日,ChatGLM1.0 开启邀请制内测。ChatGLM 参考 ChatGPT 的设计思路,在千亿基座模型 GLM-130B 中注入代码预训练,通过监督微调等技术实现人类意图对齐,具有支持双语、高精度、快速推理、 可复现性和跨平台等优势。同期开源的还有具有 62 亿参数、支持中英文双语对话的 ChatGLM-6B,虽然规模不及千亿模型,但大大降低了推理成本。 2023 年 6 月 27 日,第二代 ChatGLM 正式发布。在保留初代模型对话流畅、部署门槛低的基础上引入更加 强大的性能、允许更多轮次的对话和更长的上下文、进行更高效的推理、允许更开放的协议。2023 年 7 月 15 日,智谱 AI 宣布 ChatGLM 允许免费商用。
(4)商汤科技
商汤科技拥有深厚的学术积累,并长期投入于原创技术研究,不断增强行业领先的多模态、多任务通用人工智能能力,涵盖感知智能、自然语言处理、决策智能、智能内容生成等关键技术领域。2023 年 4 月 10 日, 商汤 SenseTime 举办技术交流日活动,分享了以“大模型+大算力”推进 AGI(通用人工智能)发展的战略布局, 并公布了商汤在该战略下的“日日新 SenseNova”大模型体系,推出自然语言处理、内容生成、自动化数据标注、自定义模型训练等多种大模型及能力。 依托自研千亿级参数自然语言模型,商汤科技 4 月 10 日发布了中文语言大模型应用平台“商量 SenseChat”。 "商量SenseChat"是由商汤科技研发的一款基于自然语言处理技术的人工智能大语言模型,具备较强的语言理解、 生成能力,可以解决复杂问题,提供定制化建议,还能辅助创作文本,同时具备不断学习进化的特性。 7 月 7 日,“商量 SenseChat”迭代至 2.0 版本,其基模型为商汤联合多家国内顶级科研机构发布的书生·浦语 InternLM-123B,拥有 1230 亿参数,在语言、知识、理解、推理和学科五大能力上均处于行业领先水平。
1.1.4 大模型行业整体发展评述
国外大模型发展趋势: 美国人工智能企业引领行业发展。美国 OpenAI 的基础大模型性能领先,目前已经在基础大模型上开始快速构建开发生态,Google 也在发力追赶过程中,Meta 通过开源大模型构建开源生态。美国在研发能力、人才储备、算力支持方面仍然占据一定优势。我们预期,海外大模型将沿着多个维度持续演进。
更大的参数量、更多的训练文本依旧是大模型的主要发展路径。 OpenAI 论文《Scaling Laws for Neural Language Models》中提出著名的缩放法则,缩放法则中提到模型表 现和规模强相关,和模型的 shape 弱相关:规模包括模型参数量 N、数据集大小 D 和计算量 C,模型 shape 指模 型 depth、width、number of self-attention heads。Palm-2 technical report 中提到,训练数据量和模型参数量大小保 持同比例增长是最优组合。 目前最先进的大模型 GPT-4 仍然高度符合缩放法则,简而言之,模型越大性能越好,训练的数据量越大模 型性能越好,这条法则仍然成立。通过单纯的增加模型参数量和训练数据量就可以实现更好的模型性能,可以 预期,在短期之内,不断增加模型参数量依旧是提升模型性能的主要手段。
更多的模态到来,开启全新的多模态时代。 文本、语音、图片等单模态人工智能模型已经相对成熟,大模型正在朝着多模态信息融合的方向快速发展。 图文多模态技术已经取得了显著的进步,未来大模型不止满足文字和图像,开始向着音频、视频等领域拓展。
大模型的逻辑思维能力可能看到飞跃式提升。 大语言模型在文本的理解和生成上表现出色,但是涉及到数理逻辑推理时表现仍然有待提升。通过思维链、 思维树的提示词工程设计,大语言模型能够将大型任务分解为较小且易于管理的子目标,内部的逻辑一致性显著增长,从而高效地处理复杂任务。
AI Agent 将成为我们接触大模型的主要媒介。AI Agent 是有能力主动思考和行动的智能体,它们能够使用传感器感知周围环境,做出决策,然后使用执行器采取行动,甚至与别的 agent 合作实现任务。OpenAI 应用研究主管 LilianWeng 提出了 AI Agent 的重要组成公式:Agent =大语言模型(LLM) + 规划能力(Planning) + 工具(Tool) + 记忆(Memory)。AI Agent 相比大语言模型的提升在于:与环境交互、个性化记忆、主动决策、合作机制。在生成式 AI 的不同应用等级中, AI Agent 是比聊天机器人更高层级的应用形态。
国内大模型发展趋势: 国内大模型行整体依旧处于跟跑状态,目前国内具备代表性的大模型在中文问答表现上已经与 ChatGPT 不相上下,短期之内仍然是沿袭海外技术路线,模型规模的不断增加和训练语料的不断扩充是当前的主要任务。 同时国内大模型的多模态能力仍处在起步发展阶段,短期之内有望看到多模态能力的快速提升。受 ChatGPT 驱动,2023 年国内大模型呈现迅猛发展局面,经历近一年时间,国内大模型实现能力上的快速进步。根据赛迪顾问,截至 2023 年 7 月,中国累计已经有 130 个大模型问世,其中有近一半的大模型在今年年内问世。 同时国内大模型的整体竞争格局也日益清晰,大致可以分为三类大模型:具备持续技术领先能力的闭源大模型、具备领跑能力的开源大模型、具备垂类场景优势的垂类大模型。大模型的每一次迭代更新都需要大量的研发投入和算力投入,在一年时间内经历多次的迭代更新,如未见显著的技术领先优势或特定场景的优秀商业模式,或将无法维系大模型的持续投入。我们认为,目前国内大模型已经经过了高速发展的扩张阶段,预期将见到模型扩张速度的下降,竞争格局更为集中。
国内大模型格局:
- 具备技术持续领先能力的大模型:优秀的大模型人才、充足的算力资源、海量的优质数据、足够的研发投入是人工智能企业具备酝酿大模型的先决条件,在快速的迭代发展过程中,部分大模型展现出持续的技术领先优势,典型如百度文心一言、科大讯飞星火大模型。
- 具备技术优势的闭源大模型具备较强的变现能力。 开源大模型:开源大模型与顶尖的闭源大模型相比有一定的技术差距,其参数量和上下文窗口长度普遍相对较小。但是开源模型借助社区的创新力量,实现了技术的快速迭代和应用拓展,成为大模型行业发展的重要支撑。
- 具备垂类场景优势的大模型:通用大模型可以帮助用户解决一般性问题,而当企业需要处理其特定行业的 数据和任务时,往往需要针对其行业数据库来对基本模型进行微调,垂直行业的特性和需求不尽相同,垂类场 景中的垂类数据是专业大模型竞争中的核心要素,专业数据驱动垂类模型百花齐放。
大模型 C 端商业模式:
- 1)以纯软件的形态输出聊天机器人、包含大模型能力的各类软件(例如 copilot)、 AI Agent(GPTs)等产品;
- 2)融合大模型能力的各类智能硬件,例如 AI pin、智能音响、翻译机、学习机等。
大模型 B 端商业模式:
- 1)出售大模型 API 接口,向公司或开发者按照调用次数收费;
- 2)直接卖大模型开发服务,向传统企业输出大模型行业解决方案获得收入;
- 3)大模型配合 AI 服务器形成软硬一体的产品,打包向传统企业输出大模型行业解决方案;
- 4)用大模型改造现有业务,提高产品的竞争力获得更多商业回报,即 Model-As-A-Service (MaaS)模型即服务。
1.2 AI 前沿技术趋势展望
1.2.1 AI Agent(AI 智能体)
AI Agent 指的是人工智能智能体,其能够使用传感器感知周围环境,做出决策,并使用执行器采取行动。 OpenAI 应用研究主管 LilianWeng 提出了重要公式:Agent = LLM(大型语言模型)+ 记忆 + 规划技能 + 工具使用。 大型语言模型为 AI Agent 带来了革命性进步,经过四大发展阶段,逐步具备了高效推理、灵活行动、强大的泛化以及无缝任务转移的能力。发展历程:AI Agent 经历了符号智能体、反映型智能体、基于强化学习的智能体、具有迁移学习和元学习功能的智能体四大发展阶段,现在已经跨入基于大型语言模型的智能体阶段。大语言模型为 AI Agent 带来了突破性的进展,同时具备了以上四大发展阶段的优势:
- 1)通过思维链(CoT)和问题分解等技术,基于 LLM 的智能体可以表现出与符号智能体相当的推理和规划能力;
- 2)通过从反馈中学习和 执行新的行动,获得与环境互动的能力,类似于反应型智能体;
- 3)大型语言模型在大规模语料库中进行预训练, 并显示出泛化与迁移学习的能力;
- 4)从而实现任务间的无缝转移,而无需更新参数。
由于大模型仍存在大量的问题(如幻觉、上下文容量限制等),并且极度依赖于用户自己给出指令,如果用户指令不够清晰,就会影响整个模型的效果。能够自己独立思考、调用工具去逐步完成给定目标的 AI Agent 会是从大模型通往 AGI 路上的下一个阶段。
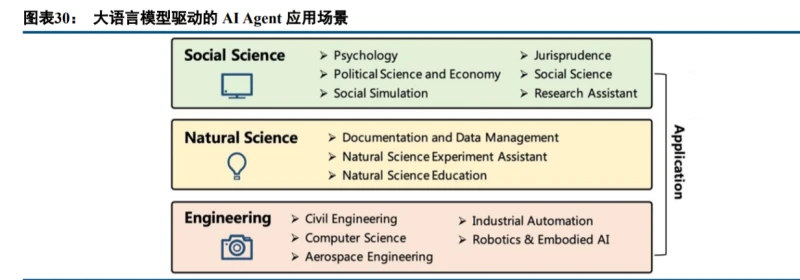
AI 智能体已经在多个下游逐步应用,包括社会科学、自然科学、工程学等领域,并表现出过去 AI 无法实现的功能和性能。 自然科学领域中,AI Agent 主要应用在科学教育中,在实验助理、文献及数据管理方面也有所应用。例如卡耐基梅隆大学的研究人员在 2023 年 8 月 14 日提出的编程教育 Agent CodeHelp,其提供了设定课程关键词、 监控学生查询以及提供反馈等功能。 工程学领域中,AI Agent 的应用最为广泛,其中机器人&具身智能、计算机科学&软件工程、通用 Agent 是最主要的应用场景。AutoGPT 是通用 Agent 的代表,其可以将设定好的一个或多个目标分解为相应的任务并循环执行。自 AutoGPT 引发广泛关注以来,相关研究持续推进,如 MiniAGI、SuperAGI、AutoGen 等。 社会科学领域中,AI Agent 应用在模拟实验、心理学、政治与经济学等场景中。例如著名的斯坦福小镇 (Generative Agents),其在虚拟城镇中构建了多个 AI Agent 来模拟人类的日常生活,大大降低了社会学实验的 成本并避免了潜在的道德风险。 大语言模型具有强大的语言理解能力、复杂任务推理能力和知识积累,这些能力让基于大语言模型的 AI Agent 在多个下游领域中展现出强大潜力,AI Agent 的发展也将让大模型的“智慧”得以应用于解决更多现实 场景的问题,拓宽 AI 应用的边界。目前 AI Agent 的技术框架已经较为清晰,后续随各环节的技术革新以及各场景数据收集等的持续推进,AI Agent 将加速发展,值得持续关注。
以下举例几个在不同领域应用的智能体实例:
1) 自然科学领域 AutoGPT&XAgent
AutoGPT 是一种开源的完全自动化智能体。AutoGPT 通过 API 结合了 GPT-3.5 和 GPT-4,允许用户创建使用语言模型来生成和改进文本。它可以阅读、写作和浏览网络,它根据任务目标自己创建 prompt,然后再完成这个任务,接下来重复这个过程直到达到最终目标。它还可以使用 GPT-4 编写自己的代码,并执行 Python 脚本以递归调试、开发、构建和自我改进。目前已开发的应用场景包括:进行市场调研、生成博客大纲、开发应用程序、搭建网站、为客户提供服务、管理社交媒体账号、成为财务顾问。 但目前 AutoGPT 的缺点也非常明显,比如 GPT4 费用较高,对于一个小任务,如果按照平均 50 个步骤来算的话,成本大概为 50 * 0.288 = 14.4 美元(约人民币 98.5 元),此外 GPT 3.5 非常容易逃逸或者陷入死循环。
2)工程学领域 MetaGPT
MetaGPT 是一个基于 GPT-4 的多智能体合作框架,该框架将人类的 SOP(标准化作业流程)编码为 LLM 智能体,并从根本上扩展了解决复杂问题的能力。设计了一个新的元编程机制,包括角色定义、任务分解、流 程标准化和其他技术设计。这样,MetaGPT 能够使用 SOP 开发复杂的软件。 核心优势:1.引入元编程框架:在构建多智能体系统时具有极高的便利性和灵活性。2.整合人类 SOP 过程 设计:减少了基于 LLM 的多智能体协作中的错误,显著提高了稳健性,使系统具备了系统化工程解决复杂任务 的能力。3.实现最先进的性能:经过对 python 游戏生成、CRUD2 代码生成和与 AutoGPT、AgentVerse、LangChain 以及 MetaGPT 一起的简单数据分析任务进行了全面实验。整体结果显示 MetaGPT 在代码质量和预期工作流的 一致性方面都优于其对手。并且,MetaGPT 有潜力解决 LLM 中的幻觉问题,从而引导协作的 LLM 系统朝更有 效的设计方向发展。
3)自然科学领域 Humanoid Agents
以往的 Agents 会根据环境制定严格的计划,但事实上这一过程与人类的思维方式并不完全相似。大多数人不会提前制定计划,然后在日常生活中一丝不苟地精确执行这些计划,原因就在于 Agent 并没有真正反映出人 类的基本需求、真实情感及人际间微妙的距离感。 为了减轻这一缺点的影响,研究者基于 ChatGPT 3.5 提出了仿人类机器人—Humanoid Agents,该模型引入 了基本需求(饱腹感、健康和能量)、情感和关系亲密程度三大概念,来让 Agent 表现得更像人类。利用这些元素,Agents 就能调整自己的日常活动,以及和其他 Agent 的对话,而且也会像人一样,遵守马斯洛需求理论。 实验表明 Humanoid Agents 对于活动是否增加饱腹感和能量;活动中表达的情感;对话是否拉近了参与者之间 的关系都能够进行很好的预测,但是在分类活动是否满足乐趣、健康和社交等基本需求方面略显吃力。 在陪伴场景下(如虚拟恋人),更了解人类情感的 Agent 可以带给人更优秀的情绪价值,提出更人性化的建议,更好得满足当代人的情感需要。
1.2.2 混合专家模型技术
混合专家模型(MoE)是一种稀疏门控制的深度学习模型,主要由一组专家模型和一个门控模型组成。MoE 的基本理念是将输入分割成多个区域,并对每个区域分配一个或多个专家模型。每个专家模型可以专注于处理输入的一部分,从而提高模型的整体性能。 门控模型:稀疏门网络是混合专家模型的一部分,它接收单个数据元素作为输入,然后输出一个权重,这 些权重表示每个专家模型对处理输入数据的贡献。例如,如果模型有两个专家,输出的概率可能为 0.7 和 0.3, 这意味着第一个专家对处理此数据的贡献为 70%,第二个专家为 30%。 专家模型:在训练的过程中,输入的数据被门控模型分配到不同的专家中进行处理,如右图所示,不同的 专家被分配到处理不同种类的输入数据;在推理的过程中,被门控选择的专家会针对输入的数据,产生相应的 输出。 这些输出(可以是标签或者数值) 最后会和每个专家模型处理该特征的能力分配的权重进行加权组合, 形成最终的预测结果。 混合专家模型在训练过程中通过门控模型实现“因材施教”,进而在推理过程中实现专家模型之间的“博 采众长”。
混合专家模型通过仅激活少数专家模型处理输入数据,提高训练和推理效率。在传统的密集模型中,对于 每一个输入都需要在完整的模型中进行计算。在稀疏混合专家模型中,处理输入数据时只有少数专家模型被激 活或者使用,而大部分专家模型处于未被激活状态,这种状态便是“稀疏”。稀疏性是混合专家模型的重要优 点,也是提升模型训练和推理过程的效率的关键。 对于稀疏性的控制,主要通过调整门控网络的设计和参数来实现。在参数选择上,如果门控网络单次选择 的专家模型数量较多,则模型的稀疏性就会降低。单次选择专家的数量越多, 模型的表现能力可能有所提升, 因为更多的专家模型处理输入数据,所以导致稀疏性有所下降,增加计算的复杂性和耗时。因此, MoE 模型 的稀疏性在效率和表现能力之间存在权衡。根据不同的应用需求和资源限制,需要适当调整门控网络的设计和 参数,来找到最佳的效率和表现能力之间的平衡。
在自然语言处理领域中,2017 年,谷歌首次将 MoE 引入自然语言处理领域,通过在 LSTM 层之间增加 MoE 实现了机器翻译方面的性能提升。2020 年,Gshard 首次将 MoE 技术引入 Transformer 架构中,并提供了高效的 分布式并行计算架构。而后的 Swtich Transformer 和 GLaM 则进一步挖掘 MoE 技术在自然语言处理领域中的应 用潜力,实现了优秀的性能表现。 Switch Transformer:通过 MoE 技术对模型进行拓展,最大版本的 Switch Transformer 的参数量高达 1.6 万 亿。因其优秀的稀疏性,在计算资源相同的情况下,74 亿版本的 Switch Transformer 训练速度可以达到 T5 模型 的 7/2.5 倍(对应 T5 模型的不同版本,Large 为 7.7 亿,Base 为 2.2 亿)。同时在多任务的表现上也取得了相比 密集模型更为优秀的结果。 GLaM:最大的 GLaM 拥有 1.2 万亿个参数,大约是 GPT-3 的 7 倍。然而,它只消耗了训练 GPT-3 所需能 量的 1/3,并在推理时只需要一半的计算浮点运算量, 计算效率更高。在零样本、单样本和少样本学习任务上 也实现了更好的性能,在七个具体任务中分别实现了平均 10.2%、6.3%和 4.4%的性能提升。
在计算机视觉领域中,2013 年的 DMoE 便是在 MNIST 数据集上使用了密集的 MoE 层,2021 年的 V-MoE 将 MoE 架构应用在计算机视觉领域的 Transformer 架构模型中,同时通过路由算法的改进在相关任务中实现了 更高的训练效率和更优秀的性能表现。 V-MoE 原理:V-MoE 通过将 ViT 中的一部分密集前馈层替换为稀疏的 MoE 层来实现,每个图像块被“路 由”到一组“专家”(MLPs)中进行处理,同时通过对图像中重要信息的优先分析(优先级路由),使得模型可 以不需要分析所有信息便可以得到较为准确的结果,对于鸭子的图片,通过将其中重要的 16 个 token 分配到 4 个专家处,便可以得到较为正确的分析,提升了模型运算效率。 V-MoE 性能:通过使用稀疏的 MoE 层,V-MoE 可以在保持性能的同时减少计算资源的使用,从而实现更 高效的模型训练和推理。在两个任务中,V-MoE 相较于 ViT 模型,达到相同性能的情况下节省了 2.5 倍的算力消耗,而在相同的算力消耗下,V-MoE 也实现了更优的性能。 同时,V-MoE 还可以用于其他计算 机视觉任务,如目标检测和图像生成。
在多模态领域中,2022 年的 LIMoE 是首个应用了稀疏混合专家模型技术的多模态模型,模型性能相较于 CLIP 也有所提升。 LIMoE 原理:将输入的图像/文本通过门控网络分配到不同的专家模型中,鸭子(drake)的图 片和对应的文字描述的 token 被分配到不同的专家中进行处理,每个专家处理完后通过输出层为图像或文本生 成一个统一的向量表示。 LIMoE 性能:在零样本和 10 样本的 ImageNet 分类任务中,LIMoE 的绝对平均性能相较于 CLIP 实现了 10.1 和 12.2%的提升,在 Coco T2I(文本到图像检索)任务上,LIMoE 也实现了较为明显的性能提升,其中在小规 模模型上这一提升更为显著。
1.2.3 机器人大模型
1.2.3.1 人工智能模型推动机器人控制革新
机器人控制系统相当于机器人的大脑,机器人控制算法则是其中的软件核心。其核心功能是处理来自传感器的检测信号,给出机器人下一步应该怎么做的指示。与传统的机械系统控制算法相比,机器人控制算法是非线性、多变量、时变的,且相较于传统机械,机器人面临的应用环境也更为复杂和多样,这意味着机器人控制算法有相当高的设计难度。 早期机器人控制算法主要采用 PID 算法,后续复杂的运动控制算法如 MPC 和 WBC 逐渐成为主流。PID 算法早在 1932 年由物理学家哈利奈奎斯特,而后便被广泛应用在各类控制领域中,包括机器人控制领域中。但由于 PID 方法本质上是线性控制器,因此无法处理较为复杂的任务。而后 1987 年提出的 MPC 算法和 2004 年 提出的 WBC 算法逐渐成为主流,让更为复杂任务的处理成为可能,但同时也还存在着计算复杂度高、算力需求高的问题。
1.2.3.2 谷歌:机器人大模型引领者
随着各项人工智能技术的不断发展,具备与物理世界交互的强大潜力的智能机器人成为学界和业界的重要研究赛道。其中 Google 依托其在 AI 领域强大的研究团队,丰厚的多领域研究成果,引领着近年来机器人模型的发展。Google Deepmind 在 2023 年 6 月和 7 月发布了其最新研究成果,具备“自我完善”能力的“RoboCat” 和融合大语言模型能力的 VLA 模型“RT-2”,机器人智能化进一步加速,有望掀起新一轮 AI 革命。 从 Gato 到 RoboCat,更大规模的训练数据集和创新的自我完善方法助力打造更强的机器人智能体。在 2022 年 5 月提出的 Gato 模型将智能体扩展到机器人控制领域中,但“通用性”和“智能性”仍有较大提升空间,其 模型架构和控制任务数据的序列化方式是后续模型发展的重要基础。2023 年 7 月提出的 RoboCat 则基于 Gato 的模型基础,将训练数据集扩充至 400 万个机器人相关片段,并创新性的提出“自我完善”的方式来进一步丰 富训练数据,这两点创新让 RoboCat 在实现了训练任务的性能提升并具备了一定的泛化性能,并且能够在少量 数据微调的情况下处理未见过的任务。
1.2.3.3 Meta:持续探索在有限数据集情况下实现更优秀机器人控制的方法
近年来,Meta 一直是 AI 领域不可忽视的力量,前沿研究如 CV 领域的 SAM 模型,NLP 领域的 LLaMa均是相关领域的最前沿技术之一。在机器人模型领域,Meta 也已经展开了较为完善的布局,提出了一些卓有成效的改进策略如数据增强、动作序列生成等,相关模型如 R3M、CACTI、ASC、MT-ACT 等,其他领域的核心突破如 SAM 模型也应用到了其中。 从 R3M 到 MT-ACT,Meta 持续探索如何使用有限的数据集实现更优秀的机器人控制。在 2022 年 3 月推出的 R3M 模型中,Meta 首次引入人类视频数据作为机器人控制模型的知识来源,提升机器人模型训练效率。 在 2022 年 12 月推出的 CACTI 模型中,使用数据增强技术实现了训练数据规模高效扩充。2023 年 8 月推出的 MT-ACT 模型将数据增强技术(基于 SAM 视觉模型)和动作序列生成技术结合,在 7500 个原始训练数据的情 况下,在不同难度的测试中分别实现了 81.67%、65.17%、31.33%的成功率,小规模数据表现优于其他可比模型。
二、AI 应用趋势展望
2.1 AI+教育是人工智能落地的黄金赛道
教育行业因为其个性化学习诉求强、数据丰富度高、付费意愿强,成为人工智能的优质落地领域。不同地区、学校和学生具备“因材施教”强个性化学习需求,教育领域的高数据丰富度为垂直大模型的训练提供可能, 同时,教育作为刚需领域,学生、家长付费意愿普遍较强。AI 的发展使得以低成本的方式建设自适应学习系统 成为可能。具备较强理解能力的生成式人工智能可以持续为学生提供个性化教学服务,且随着教学规模的扩大, 其人均成本逐渐下降,显著降低了个性化学习的成本。
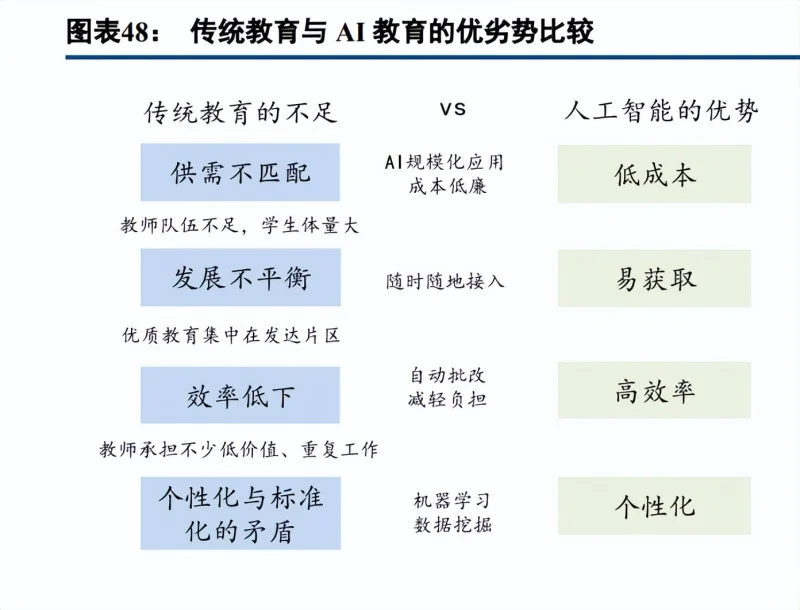
AI+教育主要有以下三点优势:
一、教学环境及课程形式的灵活化。AI 技术的引入使得教学不再局限于课堂,学生可以随时随地获得最新、 优质的学习资源,向 AI 助手请教。利用 AI 的高效多模态生成力,还可以呈现不同的课程形式营造更多的沉浸感。
二、学习过程的个性化。AI 教育平台往往具有教学、考试、批改、解答、集错等多重功能,通过分析学生 在考试过程中的用时分配、错题分类,发现学生薄弱环节,针对性提供学习资源、个性化的学习方案和改进方案,即时给予反馈和评估。借助 AI 技术,针对性辅导成本大大降低,教育更好地适应每个学生的独特需求和能力水平。
三、教学活动的降本增效。对于教育资源有限的地区,相对较低成本的 AI 教育应用使得高质量资源更加触手可及,进一步促进教育公平;对于教学者,AI 软件的批阅、评估功能大大减少了机械化劳动,使教师有更多的精力投入到创造性的教学活动中,提高了教学效率。
随着生成式人工智能技术的爆发,AI+教育迈向全新的发展阶段。根据 Market Research 数据,生成式人工 智能在教育领域的市场规模将从 2022 年的 2.15 亿美元上升至 2030 年的 27.4 亿美元,CAGR 为 37.5%,其中面向学生端的市场规模大致占到全部市场规模的一半。
国家出台 AI+教育的纲领性文件,顶层规划驱动行业稳步发展。2018 年 4 月,教育部发布《教育信息化 2.0 行动计划》,在行动规划上提出不断推动人工智能与教育深度融合,加快面向下一代网络的高校智能学习体系建设。2022 年 8 月,科技部发布《支持建设新一代人工智能示范应用场景》,针对青少年教育中“备、教、练、测、 管”等关键环节,运用学习认知状态感知、无感知异地授课的智慧学习和智慧教室等关键技术,构建虚实融合与 跨平台支撑的智能教育基础环境。2023 年 6 月,教育部发布《基础教育课程教学改革深化行动方案》,强调探索利用人工智能、虚拟现实等技术手段改进和强化实验教学以及遴选一批富有特色的高水平科学教育和人工智能教育中小学基地。
2.1.1 AI+教育软件
AI+教育软件是人工智能落地的重要领域,多邻国与可汗学院是全球市场上的领跑者。 自 2021 年起,多邻国与 Open AI 达成战略合作,推动了 AI 与教育的深度融合。在最新的 GPT-4 技术基础 上,Duolingo 于 2023 年 3 月 14 日推出了家教功能,包括 Explain My Answer 和 Roleplay 两大功能,并引入了 付费层“Duolingo Max”,旨在进一步实现“提供千人千面的个性化语言学习服务”的目标。该付费层不仅提供角色 扮演和解释答案的功能,还新增了课堂教练,为用户在提交答案之前提供小提示,优化学习体验。Duolingo 接 入 GPT-4 后,月活用户数实现大幅增长,2023Q3 月活跃用户数(MAU)为 8310 万人,同比增长 47.1%,其中 付费订阅用户为 580 万人,同比增长为 56.8%。付费用户数提升叠加会员费的提升带来公司盈利能力的不断增 强,公司 2023Q3 营业收入为 1.38 亿美元,净利润为 281 万美元,扭亏为盈。在财报电话会议中,多邻国管理 层强调他们正在利用生成式 AI 技术加速 Stories 脚本的撰写速度,使得完成任务更快、成本更低,同时质量也 不会降低。这一战略应用使得多邻国在 AI+教育领域具备独特的优势:游戏化的语言教学为其形成了差异化竞 争策略,深厚的技术积累构建了坚实的技术壁垒,同时积极将生成式 AI 技术融入产品中,优化用户的学习体验。 至 2023 年 11 月 30 日,公司股价累计上涨了 77.4%,凸显了其在 AI+教育赛道上的卓越表现。进一步印证了多 邻国在创新教育模式、提升用户体验方面的成功实践。
2.1.2 教育信息化
我国教育信息化发展从 1.0 走向 2.0 时代。
教育信息化 1.0:三通两平台是教育信息化 1.0 核心,教育信息 化 1.0 主要涉及基础设施建设。2007 年 2 月,教育部发布《教育部关于做好国家教育考试考务管理与服务平台 相关工作的通知》,提出在 2009 年高考前,在全国范围内分批建立全方位发挥作用的国家教育考试指挥、管理、 监控体系,随后一些列政策逐渐开启教育信息化 1.0 时代。
教育信息化 2.0:从基础设施建设走向信息融合与应用层面,核心是“三全两高一大”。2018 年 4 月,教育部发布《教育信息化 2.0 行动计划》,提出到 2022 年基本实现“三全两高一大”的发展目标,教育信息建设从注重信息装备建设走向信息的深度融合。
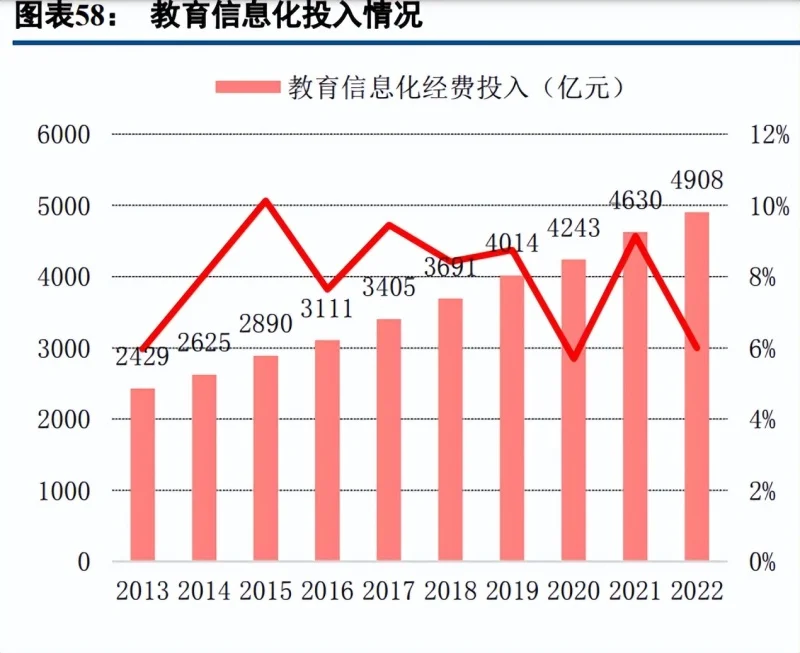
财政在教育信息化领域的经费投入是中国教育信息化市场发展的主要动力,教育信息化经费占教育经费不低于 8%,根据教育部公布的教育经费推算,2022 年教育信息化投入约 4908 亿元,2014-2021 年中国教育信息化经费投入复合增长率为 8.13%。根据《基础教育信息化发展指数》,2019 年我国教育信息化经费投入中有 42.4% 的资金都用于硬件和相关设备的购置。海外教育信息化市场属于后发市场,智能交互设备渗透率相对较低,整体空间更为广阔,市场增速相对更高。
2.1.3 教育智能硬件
智能硬件是指通过将硬件和软件相结合对传统设备进行智能化改造,对硬件与软件的优势进行了充分融合。 我国智能硬件在政策加持、技术赋能、消费升级等因素驱动下,市场规模以较高增速增长。智能硬件产品广泛应用于个人穿戴、养老陪伴、教育娱乐、运动健康等场景,为人民生活带来智能化和便利化。智能学习设备服务市场指旨在为学生提供教育服务的硬件设备市场,其最重要的特点是在提供教育服务过程中应用智能技术, 如 OCR 技术、AI 大模型应用及信息技术,以向学生及家长、教师提供更个性化的教育体验。
从应用场景的角度来看,市场可以分类为主要服务于个人终端用户的 To C 市场及提供数字校园教学解决方案的 To B 市场。2021 年,中国的智能学习设备总市场规模达到 659 亿元,预计到 2026 年,中国智能学习设备 的总市场规模将为 1450 亿元,2021 年至 2026 年的复合年增长率为 17.1%。在政府持续支持并投入实现校园数 字化及智慧课堂升级的背景下,To B 分部于 2017 年至 2021 年经历高速增长,2021 年我国 B 端市场规模达到 330 亿,2026 年有望达到 709 亿。相比而言,To C 学习市场目标人群较多,且辅助教育涵盖从早教到成人教育, 有庞大及持续的需求。2021 年 To C 分部的市场规模为 329 亿元,预计 To C 分部持续稳健增长至 2026 年的 741 亿元。
从学习机市场结构来看,以步步高和读书郎为代表的传统主流智能教育设备厂商,仍占据市场的主要份额。 以科大讯飞和网易有道为代表的新型品牌凭借人工智能技术的支持和高科技属性迅速扩大了市场规模。此外, 教育属性极强的学而思和有道等转型厂商也加入了市场竞争。根据 IDC 数据,2021 年国内市场占有率最高的步步高学习机占比高达 28.9%,第二名读书郎份额 6.1%,科大讯飞以 4.0%位列第五。
2.2 自动驾驶:算法架构优化,高阶辅助驾驶渗透率预期提升
2.2.1 端到端模型实现算法架构优化,自动驾驶性能提升
“端到端”架构是自动驾驶发展未来主流方向。意为依靠输入,直接输出,所以对输入内容要求较高。激光雷达、雷达、照相机等都是感知系统的组成部分,其中激光雷达和雷达进行深度分析,摄像机进行探测,GPS 和里程表传感器捕获并绘制车辆的位置、状态和相应的环境,进而在决策阶段进一步利用。例如,以典型端到端模型 TCP 和 UniAD 中,其都是用多种不同感知器一起使用去获取相关信息,并生成相应的控制动作。多模 态在关键感知领域的性能优于单模态,结合多传感器服务自动驾驶需求。特斯拉传统逻辑是简化输入,优化局 部算法;但为了服务端到端模型需求,算法框架演变为增强输入以优化整体算法,强化数据精准度,借助系统冗余保证可靠性。
2021 年,端到端驾驶算法出现了重要转折点。算法集中在多模态和 Transformer 等高级架构的结合,如 TransFuser 和其他变体。基于传感器对环境的精确捕捉,闭环 CARLA 基准性能逐步提高;为了提升自动驾驶系 统的可解释性和安全性,NEAT、NMP 和 BDD-X 等方法明确纳入了多种辅助模块。2023 年,研究强调优先生 成关键数据,即预先训练一个大型策略学习基础模型,如 UniAD,同时引入了新的 CARLA v2 和 nuPlan 基准。
特斯拉 FSD V12 在算法层面实现端到端。FSD Beta v12 完全是由神经网络训练而成,没有任何一行人工写 的规则代码。马斯克称,控制是全自动驾驶最后一个难题,FSD Beta v12 使用 AI 替代传统控制模块使得控制代 码减少约 2 个数量级。特斯拉原先的自动驾驶算法 HydraNets,也被成为九头蛇网络,是将每一个任务划分为单 独模块,虽然在工程学上对每一个模块进行优化,但却没法从全局提升汽车自动驾驶性能。 我们认为端到端将感知、预测与规划集成在同一个网络流程中,将自动驾驶建模成一个神经网络驱动任务。 端到端使得算法中的所有模块都直接服务于规划,使得最终汽车做出规划的效率提高,避免了模块分散导致的 数据重复流转。马斯克表示 HW4.0 硬件目前暂时不受支持,主要原因是两者数据不兼容,未来仍需针对 HW4.0 进行重新训练。马斯克称目前制约训练的因素不是工程师,而是训练算力。特斯拉在 7 月份投产 Dojo,规划到 2024 年 100E 算力(相当于 30 万颗 A100 算力),预计 2024 年 2 月自身算力规模将进入全球前五;同时特斯拉 新到一批英伟达机器,训练算力将大幅增强。
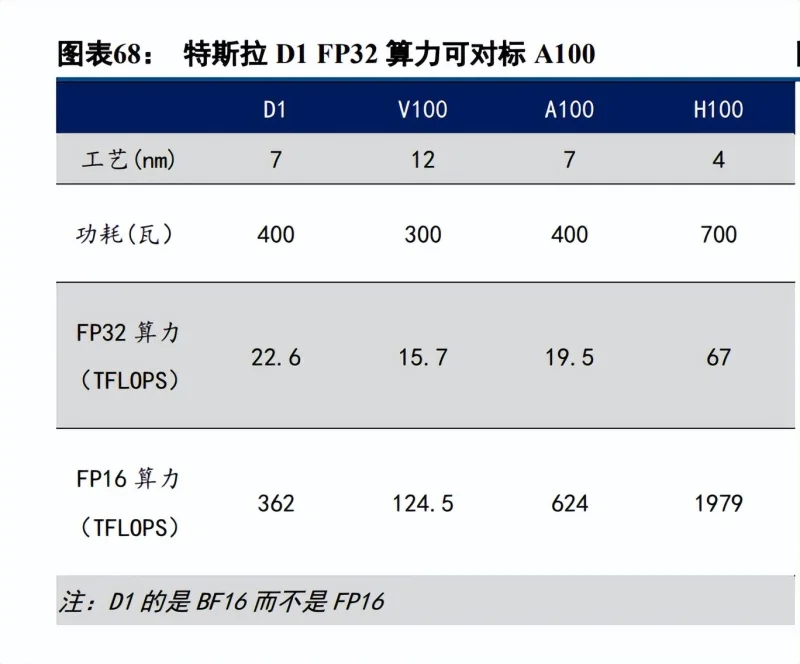
2.2.2 国内自动驾驶车厂势头依旧,高阶辅助驾驶渗透率预期提升
国内自动驾驶车厂布局迅速,L3 级别及以上渗透率有望逐步提升。2023 年 1-10 月,理想、小鹏销售量持续走高,其中理想 10 月交付量达到 40422 辆,远超其他两家;蔚来自 7 月起回落幅度较大。伴随智能化策略推进、辅助驾驶功能强化,蔚小理三家英伟达 Orin 芯片占比将持续提升。在具体配置路线上,理想更为清晰,其分 Pro 和 Max 两大车型向下向上渗透市场,其中 Max 车型提供全场景智能驾驶,标配英伟达双 Orin X 芯片渗透率将继续上升。2023 年交付量预测方面,理想预计全年销售 30 万辆,蔚来预计全年销售 24.5 万辆,小鹏预计全年销售 20 万辆。
9 月 12 日,华为正式发布问界新 M7 系列。硬件层面问界新 M7 配备 1 个顶置激光雷达、3 个毫米波雷达、 11 个高清视觉感知摄像头及 12 个超声波雷达等 27 个感知硬件。问界新 M7 通过搭载 ADS 2.0,汽车感知能力 有明显提升:通过 GOD2.0 系统,对车外物体进行识别;通过 RCR 网络,进行道路拓扑推理,摆脱高精度地图。 问界新 M7 在安全性方面亦有较大提升。根据发布会介绍,主动安全方面,问界新 M7 首发全向防碰撞系统, 问界包揽各类主动安全评测第一名;被动安全方面,问界新 M7 车身结构匹配开模,重新改造焊装产线,有效 提高车身刚度和碰撞安全性。ADS 2.0 自 2023 年 4 月发布以来,在 AI 训练集群上构建了丰富的场景库,每天 深度学习 1000 万+km,持续优化迭代智能驾驶算法和场景策略,模型每五天迭代一次,训练算力达到 1.8EFlops。 截至 2023 年 9 月数据,长距离 NCA 领航 MPI 高达 200km,城市高架汇入汇出成功率高达 99%+。到 23 年年底, ADS2.0 无图城区商用计划扩展到全国。11 月 9 日,华为宣布其问界新 M7 实现 86000 大定,其中 70%以上用户 选择智驾版,智能驾驶功能已成为消费者购车的重要决策因素之一。另外,11 月 15 日,小米汽车第一款车型 SU 7 申报,预计 2024 年上半年正式量产。
2.3 AI PC/Phone:端侧 AI 发展,AI PC/Phone 将开启新时代
2.3.1 技术升级带动端侧 AI 发展,推理精度提升
当前云侧 AI 呈现向端侧 AI 的转型趋势。端侧智能化的核心在于数据、底层软硬件、智能力三个方面。端侧设备搭载的传感器、芯片、算法模型赋予其数据采集、计算、分析与推理能力,使其能够在端侧完成数据处理闭环,形成感知、计算、推理三个智能力。 首先,大模型轻量化带动端侧 AI 发展。多个大模型均已推出“小型化”和“场景化”版本,提供了端侧运 行基础。例如,Google PaLM2 中包含 4 个大模型,按照参数规模,从小到大排列为:独角兽(Unicorn)、野牛 (Bison)、水獭(Otter)和壁虎(Gecko)。其中,最轻量的“壁虎”可实现手机端运行,且速度足够快,不联 网也能正常工作。另一方面,“小型化”大模型加速生成式 AI 垂直方向发展,加速大模型商业化场景落地。
其次,支持 INT4、INT8 精度推理,端侧 AI 能力进一步提升。定点表示和浮点表示是计算机中常用的数据格式。其中,定点表示中小数点位置固定不变,常用的定点表示有 INT4 和 INT8;浮点表示中包括符号位、 阶码部分、尾数部分。符号位决定数值正负,阶码部分决定数值表示范围,尾数部分决定数值表示精 FP64(双精度)、FP32 (单精度)、FP16(半精度)的数值表示范围和表示精度依次下降,运算效率依次提升。高通产品管理 副总裁 Asghar 曾表示,如果将 32 位浮点模型转化为 INT4 整数模型,端侧 AI 能效将提升 64 倍。为满足端侧 AI 的计算需求,业内已有产品支持 AI 模型以 INT 精度推理,例如高通人工智能引擎 AI Engine 支持 INT8 的数 据格式。
部分 AI 框架已支持端侧运行。在 2023 年 PyTorch 大会上,Meta AI 与 PyTorch 基金会合作的 ExecuTorch 模型被宣布可在边缘和移动设备上实现 AI 推理。随着 ExecuTorch 的开源,AI 应用程序将可实现本地运行,无 需连接到服务器或云。ExecuTorch 可被理解成 PyTorch 平台,提供基础设施来运行 PyTorch 程序,实现从 AR/VR 可穿戴设备到标准的 iOS 和 Android 设备的移动部署。目前,Meta 已将其用于最新一代的雷朋智能眼镜,成为 Quest 3 VR 头显的组成部分。这一变化也预示将 PyTorch 引入了手机和可穿戴设备等边缘计算平台,进一步迈 入设备 AI 推理新时代。 端侧 AI的核心是 AI PC/Phone。一方面,AI PC/Phone主要在于芯片升级。AI PC/Phone 相对于原有PC/Phone, 主要差别在搭载了相关的 AI 芯片。云端在深度学习的训练阶段需要极大的数据量和大运算量,为满足运算需求, 云端 AI 芯片采用“CPU+加速芯片”的异构计算模式。不同于数据中心 GPU,手机/电脑端芯片主要要求其体积 小、功耗低等特点,往往是采用 ASIC 技术路线的芯片,这种芯片为专用目的设计,面向特定用户需求定制, 在大规模量产的情况下具备体积更小、功耗更低等优点。
手机 AI 芯片主要由“CPU+GPU+NPU”构成,通过集成多个模块,做到提升芯片性能的同时能支持相关 AI 应用算法。例如,以高通 AI 芯片为例,硬件方面 HEXAGON 向量处理器可以运行涉及向量数学的应用; ADRENO GPU 运行对浮点精度有要求的应用;KRYO CPU 支持相对较少向量处理、非规则性数据结构和/或复 杂流程。高通公司以近半的市场份额保持 AI 智能手机处理器出货量领导地位,远超苹果和联发科等其他公司。 高通骁龙 8 gen3 在手机芯片性能比较方面超越了苹果 A17 Pro,其是高通首款专为生成式人工智能而精心设计 的移动平台。该处理器最大的升级在 AI 引擎,可以在设备上运行生成式 AI 模型,上市初期即支持 20 多种 AI 模型;主打各种 AI 相机功能,例如从图像和视频中删除对象、创建假背景、增强照片的某些部分、实时拍摄 HDR 照片、创建同时使用前摄和后摄拍摄的 Vlogger 视图模式控制的应用。
2.3.2 2024 或成 AI PC/Phone 元年,AI PC/Phone 趋势刺激行业回暖
端侧 AI 核心在于手机和 PC,AI Phone 和 AI PC 将开启新时代。从今年 2 月份举行的世界移动通信大会, 高通展示了其手机端离线运行大模型,到 5 月份微软开发者大会高通展示其 PC 运行 AI 大模型,再到近期英特 尔、联想等发布 AI PC 加速计划、发布首款 AI PC 等,可以看出,国内外厂商持续发力 AI Phone 和 AI PC, 端侧 AI 将走入新的时代。 AI PC 方面,2023 联想 Tech World 创新科技大会进行了端侧大模型与云端大模型的比较。两个模型同时进 行斯德哥尔摩音乐节的规划,生成速度差异不大。值得注意的是,端侧 AI 的规划内容更加个性化,可以将家庭 地址、酒店偏好等考虑进去;10 月 19 日,英特尔宣布启动 AI PC 加速计划,该加速计划旨在为相关软硬件供 应商提供英特尔的资源,共同推动 AI PC 产品、方案落地,具体而言,通过利用 Intel Core Ultra 处理器的技术 和兼容硬件,围绕相关资源,实现 AI 和机器学习(ML)应用性能最大化,进而催生全新的使用案例,推动 AI PC 解决方案连接到更广泛的 PC 产业。英特尔预计其将于包括 Adobe 在内的 100 家独立软件供应商进行合作, 发展 300 多项 AI 加速功能,计划将在音频效果、内容创建、游戏、安全、直播、视频协作等方面继续强化 PC 体验。据计划目标,其将在 2025 年前为超过 100 万台 PC 带来人工智能(AI)特性。
AI Phone 方面,10 月 4 日,谷歌发布 Pixel 8 / Pro 系列,搭载了 Tensor G3 和 Titan M2 安全芯片。Tensor G3 AI 芯片可运行更复杂的机器学习模型,强化了 Pixel 8 / Pro 系列的 AI 增强功能,使虚拟助理说话更自然,并有 拦截骚扰电话、转录语音和紧急服务功能。Pixel 8 Pro 号称是第一款直接在设备上运行谷歌 AI 模型的手机,其 计算量是 Pixel 7 上最大 ML 模型的 150 倍;10 月 26 日,小米 14 系列发布,其首发搭载高通最新一代移动芯片 骁龙 8 Gen3,能效比提升显著,AI 性能提升 98%。通过本地端运行大模型,提升了隐私性,并实现 AI 妙画、 AI 搜图、AI 写真和 AI 扩图等一系列功能。其中,AI 写真功能可通过对多张照片的学习,创作出全新的照片 作品;在 14 系列的 WPS 上,也支持输入主题一键生成 PPT 演示文稿,也能进一步细化调节,例如更改主题风 格、单页美化、更改字体、更改配色、生成演讲稿等等,解决了用户使用 PPT 制作难度大、耗时长的办公难题。
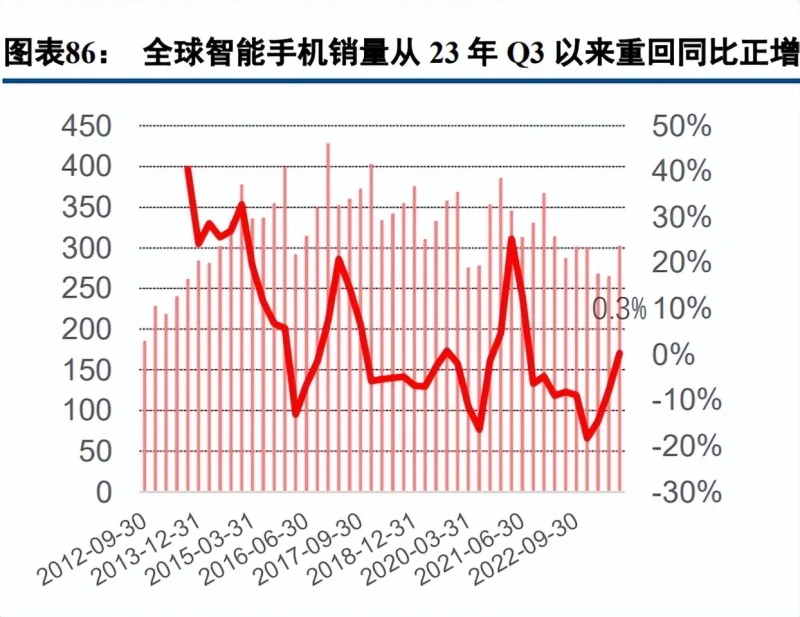
疫情以来,由于消费需求疲软和库存调整,全球智能手机出货量下滑,2023 年前三季度为 8.4 亿部,仅为 2022 年同期的 85%,但可以看出,22 年年底以来,全球智能手机销量下降幅度开始缩窄,今年三季度,全球 智能手机销量重回正增长;另一方面,从微软财报可以看到,其个人电脑业务,也在 24 财年 1 季度(23Q3) 实现同比正增长,这也是从 23 财年 2 季度以来微软个人电脑业务重新回归正增长。可以看到全球手机与电脑业 务有复苏迹象,预计 AI+Phone/PC 能进一步推动行业颓势逆转的同时也有助于带动其自身起量。
伴随 AI PC 逐渐出货且 PC 换机周期已至,2024 或成 AI PC 元年。根据群智咨询预测,到 2027 年,AI PC 出货量将达到 1.5 亿套,市场渗透率达到 79%,并逐步取代传统 PC。当前,各大主要 PC 厂商都对 AI PC 业态 进行展望,AI PC 将成 PC 行业拐点成为共识。戴尔将推出带有 Copilot 的新版 Windows,联想首批搭载英特尔 Meteor Lake 芯片的 AI PC 也已推出。业界将逐步追加 AI PC 领域投资,重塑 PC 生产力。
我们看好由 AI PC/Phone 带来的产业革新。将手机集成 AI,不仅可以实现语音助手、智能相机等基本功 能,还可以通过 AI 算法实现更加智能化的应用,如智能推荐、智能翻译等,可以极大提升用户的体验,在智 能办公、智能教育领域预计将有广泛应用;AI PC 不仅可以进行高效的数据处理和计算,还可以通过机器学习 和深度学习等技术进行自我学习和优化,从而为各种行业提供更加智能化的解决方案;除此之外,AI PC、AI Phone 通过统一的大模型,实现全系统互联,具有主动智能、全模态感知能力,在人机交互效果上有明显提升, 将成为人们最直接的 AI 助手。
2.4 AI+工业是大势所趋
AI 在垂直领域的落地和应用将是 2024 年的主线,我们尤其看好 AI 在工业场景的落地。一方面在国家战略和政策端,智能制造是大势所趋,“AI+工业”在国家发展、技术架构中发挥重要作用。
1)工业大国向工业强国转型,智能制造战略是必由之路。
工业与制造业紧密相连,制造业是工业的重要组成部分,工业和制造业的 发达程度将直接影响我国国际竞争力。中国是世界第一工业大国,具有优秀且深厚的工业基因。从工业大国向 工业强国的转型之路是当下政策的热点,也是未来重要的发展趋势,智能制造战略是这一路径上的核心战略之 一。《“十四五”智能制造发展规划》、《中国制造 2025》等政策进一步明确智能制造的发展目标、重点领域、重 大工程、重大项目,为智能制造的发展提供了政策支撑。
2)“AI+工业”在智能制造系统与技术架构中处于核 心地位,是战略发展的大趋势。
从系统架构层面看,智能制造系统的架构从底层数字化逐步过渡到网络化,最 终目标为实现智能化,“AI+工业“处于系统架构顶层的“智能化”位置,工业场景下人工智能技术的应用是智 能制造战略需要实现的核心课题。从技术结构层面看,人工智能技术与工业大数据、工业软件、工业云、边缘 计算等其他技术之间存在联动效应。
3)工业 4.0 时代到来,“AI+工业”技术是国际竞争焦点。
工业 4.0 时代下, 利用物联网、云计算等多元化先进技术实现实体世界与虚拟世界的交互将成为工业发展的重要环节。目前,全 球主要的工业国家在先进制造/智能制造方面均有布局,且均有涉及“AI+工业”的具体战略。我们认为,在未来,AI 技术与工业的深度融合仍将是国际竞争的焦点,实现 AI+工业是大势所趋。
从需求端看,不断增长的降本增效需求与多变的市场环境为“AI+工业”带来广阔的市场空间。目前,我 国工业的大部分行业仍处于劳动密集型发展阶段,较低的智能化渗透率带来包括误差率高、生产效率低、生产成本高等一系列痛点。
1)降本增效需求驱动“AI+工业”需求:中国单位劳动产出在国际比较中处于较低水平, 2018 年美国劳动生产率为 11.3 万美元,而中国仅为 1.4 万美元。且国内老龄化趋势显著,根据国务院《国家人 口发展规划》,2030 年,我国 14-45 岁人口占比将降至 32%,人口规模的减少将对企业生产成本带来全新挑战, 降本增效需求愈发成为企业竞争甚至生存的重要条件之一,在此背景下展望未来,“AI+工业”这一降本增效的重要工具将被越来越多工业企业使用。
2)市场变化大,精准化生产成为刚需:工业行业整体面对利润率低,市场需求变化快的压力,智能化与精准化生产将成为未来大趋势,而这背后离不开人工智能的强大分析能力。根据德勤预测,2018-2025 年中国制造业人工智能市场有望实现 51%的 CAGR,并在 2025 年达到 141 亿元规模。
2.4.1 工业机器视觉
2.4.1.1 机器视觉产业宏观分析
工业机器视觉是软硬件一体化的集成系统,它的目的是代替人眼对被测物进行观察和判断。从组成上,机器视觉系统硬件设备主要包括光源、镜头、相机等,软件主要包括传统的数字图像处理算法和基于深度学习的图像处理算法。
成像、算法、算力、应用接力驱动机器视觉行业,AI 算法的发展有望推动行业进入新时代。每经历约十年, 机器视觉技术与应用都会产生一次深刻变革,近年来,AI 算法有望推动行业爆发式扩展。
此外,过去的工业机器视觉系统主要针对垂直场景的少量数据进行小模型的训练,而大模型的发展将助力工业机器视觉实现应用性能的提升和应用场景的拓宽。以华为盘古大模型在矿山场景的应用为例,其建立在 L0 的基础大模型的技术上,通过导入海量无标注的矿山场景数据进行预训练,盘古矿山大模型即可进行无监督自 主学习,仅一个大模型就能覆盖煤矿的采、掘、机、运、通等业务流程下的 1000 多个细分场景,让 AI 应用在 煤矿普及更容易。在准确率方面, 基于盘古矿山大模型的掘进作业序列智能监测,动作规范识别准确率超过 95%,用规范的 AI 流程来替代不确定的人工流程,让 AI 成为矿工规范作业的好帮手,保障井下作业安全。 视觉大模型技术突破,赋能机器视觉的革新与突破。以近期 Meta 提出的 SAM 模型为例,其在切割任务的 不同具体场景中展现出了强大的泛化能力,在零样本(zero-shot)和少量样本(few-shot)的基础上便能实现非 常优秀的完成不同的切割任务。同时,SAM 模型还具备高精度自动标注的能力,带来数据标注成本的下降,相 关技术的发展与突破将从两个方向赋能机器视觉产业变革:1)过去数据成本、训练成本高的场景将有望实现降 本增效;2)过去因样本数量不足而机器视觉难以应用的场景将得以拓展。
除人工智能技术的变革外,2D 到 3D 的变革同样带来技术能力和应用范围的提升。相较于 2D 机器视觉, 3D 机器视觉可以提供三维信息,从而实现更广泛、准确的检测与分析。3D 机器视觉可以完成许多 2D 机器视觉无法完成的任务。3D 相机可以得到表面凹凸的深度信息,从而准确的判定划痕和边缘的凹陷。 3D 机器视觉覆盖场景全面,市场空间广阔。目前 3D 视觉技术在高精度检测、高精度测量(例如弯管、不 规则件)、智能分拣、装配(引导机械臂在三维空间内避障和定位)、物流车导航等更多场景中实现了相较于 2D 机器视觉更为广泛的应用覆盖,具有广泛的市场空间,根据 GGII 测算,中国工业 3d 视觉 2021 年市场规模 11.51 亿元。随着我国高端制造业的发展,国内 3D 视觉的应用需求仍将持续保持高增长势头,预计到 2025 年达到 57.52 亿的市场规模。
2.4.1.2 机器视觉产业链分析
机器视觉行业上游环节价值量大。关键零部件和软件系统约占工业机器视觉产品总成本的 80%。工业相机、 底层软件算法等技术壁垒高,利润率高。对机器视觉上游环节的掌握是目前市场竞争的关键。同时,相机、镜 头、光源等核心零部件部件在机器视觉产品中的占比超过 50%。 国产低端零部件逐步实现国产替代,高端部件有待突破。技术门槛相对较低的零部件如光源,国产厂商凭 借性价比优势及逐步体现的产能优势在市场竞争中逐渐实现对于国外品牌的替代。技术门槛较高的零部件如光源及相机,我国企业进入较晚,目前产品仍主要布局中低端市场,高端市场仍主要被国外品牌占据。
机器视觉上游零部件厂商和中游系统/设备厂商通过产业投资/自主研发等方式逐步拓展产业链上下游布局, 以期进一步提升机器视觉产品性能,同时在竞争逐渐加剧的机器视觉行业中构建起更高的技术护城河。 奥普特、海康机器人通过自主研发实现了机器视觉核心零部件、软件算法的全覆盖。凌云光通过产业投资 方式拓展 CMOS 传感器芯片(长光辰芯)和工业镜头(长步道光电)布局,并自主开发特色相机、特种相机、 特色专属光源和图像采集卡;天准科技自主开发 3D 视觉传感器(线激光传感器),精密驱动控制器等视觉设备 上游零部件。 我们认为,在机器视觉相关的光学成像、软件算法、自动化与精密控制等核心技术方面具有更深厚积累的 公司在竞争加剧、上下游互相渗透的发展格局中具备更强的竞争优势,头部的国产机器视觉厂商已经具备了和 海外龙头相当的全产业链技术。
下游应用场景中,机器视觉在锂电行业的渗透率逐步提升。随着锂电池制造智能化、自动化程度的提升, 机器视觉产品开始广泛地应用于锂电池设备生产的各个工段。从前段工艺的涂布辊压,到中段工艺的电芯组装, 再到后段化成分容之后的检测以及模组 PACK 段,机器视觉应用渗透率在逐步提升。 品质管控需求明确,早期的锂电行业扩产往往较少考虑质量管控,但随着行业逐步从高速发展转向高质量 发展以及用户对于锂电安全的更高需求,机器视觉已经成为锂电池生产企业解决质量和效率问题的必然选择, 据 GGII 预测,锂电机器视觉检测系统市场规模将保持高速增长,未来 5 年年复合增长率在 40%。 竞争格局优秀,在 3C 电子和汽车等行业中的机器视觉中海外巨头有着更加强的技术积累和长期合作关系, 对于我国机器视觉企业的市场拓展产生一定阻碍,但锂电池行业是近年来在我国发展起来的新兴产业,因此其 中锂电企业与我国机器视觉企业协同配合发展而来,国产化程度较高。 我们认为,锂电行业行业整体增速较快,且锂电中的机器视觉具备行业增速高、需求明确、竞争格局优秀 的优势,在未来两三年内有望维持高增速,是最具潜力的下游应用市场 。
2.4.2 工业机器人
2.4.2.1 移动机器人
AGV(Automated Guided Vehicle),即移动机器人,是工业机器人中的重要种类。AGV 可以在没有人工干预的情况下,按照可配置的导引路径进行移动和定位;糅合了导航、移动、多传感器控制、网络交互等一系列 功能。AGV 在制造业、仓储物流等工业场景有着广泛的应用,可以提高生产效率、降低劳动成本、减少产品损 坏、提高安全性。其主要应用场景仍然在搬运领域。 随着人工智能技术发展,AGV 的环境感知能力与灵活运动能力不断提升,新一代自主移动机器人 AMR (Autonomous Mobile Robot)应运而生。相比 AGV,AMR 可以融合多重传感器,具备深度感知能力和强大计 算能力,安全性和行驶的效率相对更高。
行业持续高速增长,发展势头强劲。从总量来看,2015 年到 2022 年,中国工业应用移动机器人市场规模 保持 7 年连续增长,CAGR 为 35.14%,2022 年中国工业应用机器人市场规模达到 76.8 亿元。从增量来看,中 国工业应用移动机器人产量逐年增加,2022 年增量为 93000,同比增长 29.17%。
海外销售规模不断增长,中国 AGV/AMR 产品全球影响力进一步提升。2022 年,中国 AGV/AMR 企业在 海外市场的销售规模进一步提升,2022 年,中国 AGV/AMR 企业海外销售规模为 36 亿,同比增长 44%,占比 19%。从 2019 年中国 AGV/AMR 海外销售额首次突破 10 亿人民币到 2022 年的 36 亿人民币,中国企业整 体海外销售占比取得显著提升。
行业集中度高,大型企业占比接近九成,过亿企业数逐年增长。2022 年度,中国工业应用移动机器人企业 中,年销售规模亿元以上的大型企业占据了 89.19%的市场份额,行业集中度高。行业向上的发展态势带动销售 过亿企业数量逐年增长,从 2018 年的 10 家增长至 2022 年的 42 家。截至 2022 年,中共工业应用移动机器人企 业中,有 4 家越过 10 亿门槛,分别是新松机器人、极智嘉、海康机器人以及海柔创新。
2.4.2.2 焊接机器人
焊接机器人是一种能够自动执行焊接(包括切割和喷涂)任务的工业机器人。根据焊接方式、结构形式、 负载能力、工作范围等因素的不同,焊接机器人业有不同种类。焊接机器人广泛应用于钢结构、航空、造船、 电子、机械等行业,可以提高焊接质量、效率和安全性,涉及的技术包括焊接电源技术、传感器技术、离线编 程技术、智能控制技术、仿真技术等。
国内弧焊焊接机器人市场由外资主导,国产替代需求大。根据高工机器人研究所统计,2022 年外资弧焊机 器人仍占据主要份额,占比 54.97%,在汽车整车和零部件领域应用较多,主要分日系、欧系、国产三大派系。 日系品牌主要有安川、发那科、OTC、松下、川崎重工等,欧系品牌包括 KUKA、CLOOS 和 ABB 等;而国产 品牌则在程机械、二三轮车、五金家具、钢结构等一般工业行业应用较为广泛。 国内自主品牌弧焊工业机器人市场份额逐步提升,与外资品牌差距逐渐缩小。2022 年,国产弧焊机器人份 额已达 45.03%,同比增长 23.71%,国产替代速度加快。目前市场上尚未有成熟应用于钢结构行业领域的智能焊 接机器人,主要潜在竞争产品为示教焊接机器人和进口智能焊接机器人。
焊接机器人销量持续增长,钢构行业市场较为空缺。高工机器人产业研究所(GGII)统计数据显示,2021 年国内市场焊接机器人销量为 4.16 万台,同比增长 21.99%,主要集中应用于汽车及 3C 电子领域,钢结构领域 应用程度不高,而钢结构行业对于自动化、智能化焊接方案的需求日益迫切。预计 2026 年焊接机器人销量可达 到 10.3 万台,复合增长率达 16.38%。 海外焊接机器人进展迅速,“机器人四大家族”是行业龙头,ABB 集团与发那科公司经营业务有亮点。1) ABB 集团:ABB 是工业机器人的先行者以及世界领先的机器人制造厂商,在 1994 年就进入了中国市场。经 过近 20 年的 发展,在中国,ABB 先进的机器人自动化解决方案和包括白 车身,冲压自动化,动力总成和涂 装自动化在内的四大系统 正为各大汽车整车厂和零部件供应商以及消费品、铸造、塑 料和金属加工工业提供 全面完善的服务。 2021 年,ABB 机器人为宇通打造一键式操作智能焊接工作站,基于本地自主开发免示教编 程系统,无需视觉识别即可自动生成包含有工艺参数的轨迹程序,完成不同规格的铝框的智能化生产。2)FANUC (发那科): FANUC 公司创建于 1956 年的日本,是当今世界上数控系统 科研、设计、制造、销售实力强大 的企业。FANUC 机器人产品系列多达 240 种,负重从 0.5 公斤到 1.35 吨,广泛应用在装配、搬运、焊接、 铸造、喷涂、码垛等不同生产环节,满足客户的不同需求。
智能化焊接市场需求迫切。1)钢构产业焊接技工招工难且成本高,供给需求缺口大,对自动化、智能化 焊接方案的需求迫切。国内钢结构产业渗透率持续提高,产品产量增加带动钢结构焊接市场需求。而钢结构主 要应用于建筑、船舶、重工行业非标小批量工件多的工业场景中,焊接工序自动化程度低,基本大部分依赖大 量焊接工人完成焊接。人工焊接技术要求高、技工培训周期长、焊接工作环境恶劣,已成为行业中最紧缺的劳 动力之一,焊接工人缺口量逐年递增,复合增长率高达 50%。2021 年国内熟练焊工的年薪已达 18 万元,对企 业带来较大的成本压力。2)智能化焊接可以保证焊接质量稳定,提高生产效率。传统人工焊接受人为因素影响 较大,焊接质量稳定性差,生产效率低,且钢结构加工涉及组立、矫正、装配、打磨、抛丸、表面防腐等多道 工序,整个生产过程不透明,对生产进度、生产质量和生产异常的处理缺乏信息化管控,产品交付时常延期, 实现智能化焊接是提高生产效率和产品质量。
免示教智能焊接机器人符合钢结构行业需求。钢结构产业是典型非标生产行业,产品基本全为非标定制化 生产。钢结构生产原材料基本为钢板、 钢管等,但由于规格、性能指标等因素的存在,原材料种类多,且受到 客户需求、政策和设计师习惯的影响,每个部件的加工内容、方式及尺寸都有特定的要求。钢构行业以中厚板 焊接为主,对设备精度和机器人技术要求高。大多应用弧焊机器人。 免示教机器人适合钢构行业小批量非标柔性加工场景。传统示教再现型机器人通过执行示教程序进行重复 性工作,对焊接工件一致性要求较高,且需要人工引导机器人进行预期动作编辑,多用于重复、标准化加工中, 如汽车、摩托车加工,对非标产品操作耗时长、效率低。免示教智能焊接机器人融合智能感知、智能规划、智 能控制等技术,构成以知识和 推理为核心的智能焊接系统,通过与智能技术、工艺数字化技术等先进技术融合, 实现了面向不同作业场景、作业任务、作业工艺,与钢构行业焊接需求高度契合。
2.4.3 工业软件
2.4.3.1 工业软件行业总览
工业软件是工业创新知识长期积累、沉淀并在应用中迭代进化的软件产物。工业软件的根基仍然是工业行业本身,有赖于正向创新和行业创新知识的积累,是一个长期系统工程。任何工业知识都必须先形成完整的体系,搭建出知识库和模型库,并在实践中反复应用、更改,与工程紧密结合并不断更新迭代,才有可能形成工 业软件。因此,工业软件是工业创新知识的载体,依靠软件化这一关键过程,通过强大的软件工程能力才得以 实现。软件平台与架构将直接决定工业软件产品的生命力。 工业软件可分为四大类,分别为研发设计软件、生产控制软件、信息管理软件和嵌入式软件,在工业生产 流程中发挥着不同的作用
1)研发设计软件:面向各类工业品研发、设计、加工的基础软件,提高开发效率、 降低开发成本、缩短开发周期。
2)生产控制软件:基于工业生产的流程,负责生产的流程调度、流程控制、流 程监控,提升产品生产的自动化和智能化程度。
3)信息管理软件:服务于产品的“进销存”环节信息以及企业 整体的业务管理信息助力企业实现数字化管理。
4)嵌入式软件:嵌入在硬件中的操作系统或开发工具软件,提 高生产装备智能化水平。
根据工信部、中国电子信息产业统计年鉴数据,我国工业软件增速持续领先于全球工业软件市场。2022 年, 我国工业软件产品收入 2407 亿元,同比增长 14.29%。2018 年至 2022 年,我国工业软件产品收入年复合增长率 高达 16%。 目前制造业企业信息化率仍较低,未来仍有较大发展空间。从现阶段看,我国制造业企业信息化率仍较低, 《2018 年中国制造业痛点分析报告》数据显示,制造业企业的数字化设备联网率仅为 39%、MES 普及率只有 18.1%。而《智能制造装备产业“十三五”发展规划》指出,到 2020 年,重点领域数字化研发设计工具普及率 达到 70%以上,关键工序数控化率达到 50%以上,数字化车间/智能工厂普及率达到 20%以上,我国工业软件行 业未来仍有较大发展空间。从 ERP 的普及率来看,Gartner 的数据显示,我国 ERP 的普及率(ERP/GDP)仅为 0.015%,远低于美国的 0.059%。目前 3C、汽车、家电、化工、电力等行业是 IT 投入主要领域。其中,3C 行 业前五大企业连续三年 IT 投入成本最大,达到 450 亿元。
2.4.3.2 工业软件行业聚焦:CAD——计算机辅助设计
CAD 软件是工业软件中最关键、技术门槛最高的一类软件,市场空间广阔,增长态势良好。CAD 软件承接产业链上游硬件设备、操作系统、开发工具等行业,服务下游发电、建材、化工、冶金、煤矿等应用领域;涉 及数学、物理、计算机及工程四大学科的专业知识,具备较高的技术壁垒。从上世纪五六十年代发展至今,CAD 从最初的机械制造逐渐拓展到建筑、电子、汽车、航天、轻工、影视、广告等诸多行业领域。Autodesk、Dassault、 Siemens、PTC 等厂商凭借技术优势和长期的市场积累占据主导地位,全球 CAD 市场增长趋于稳定。 全球工业软件及 CAD 行业发展态势向好,国内工业软件及 CAD 行业保持增长态势。工业软件,特别是 CAD 软件,具有应用广泛、学科知识跨度广、技术壁垒高等特点,增长态势向好。近五年,全球工业软件市场 规模与 CAD 市场规模保持稳定增长,其中全球 2016-2023 年 CAD 市场规模预计将实现 6.03%的 CAGR;国内 得益于数字经济东风与国产化替代浪潮,工业软件与 CAD 行业向上态势明显。
CAD 发展有赖于技术革命,关键技术的研发将是未来 CAD 行业竞争焦点,国产 CAD 软件进步空间大。 CAD 行业发展史也是技术革命史,从 2-2.5D 模型到三维框线模型,从曲面造型技术到实体造型技术,从参数化 技术到变量化技术,不同时点的技术进步既带来行业的腾飞,也造就新的行业龙头,放眼未来,CAD 行业的发 展仍将聚焦于关键技术的研发上。
CAD 与 AI 结合是产业新趋势,可以提高设计效率、优化设计质量、创造新的设计形式。第四范式的“式 说”大模型是一个基于生成式 AI 的新型开发平台,具备文本、语音、图像、表格、视频等多模态交互及企业级 Copilot 能力,以生成式 AI 重构企业软件(AI-Generated Software),提升企业软件的体验和开发效率。式说大模 型可以用来辅助或自动生成 CAD 3D 模型,用户通过自然语言交互就可以调用工业软件的功能,辅助完成设计。
回望海外 CAD 龙头的发展史,可发现其竞争优势各异,但核心技术的发展与对于用户使用体验的关注是共同主线。海外三大 CAD 巨头中,达索系统具有一体化+云化平台 3DEXPERIENCE,同时具有功能各异的几 何内核 CGM+ACIS,由此产生差异化 CAD 产品 CATIA+SOLIDWORKS,共同推动其占领不同类型市场,取得 领先地位。Autodesk 公司通过多次技术转型构造竞争壁垒,同时不断更新迭代产品应对需求,不断改革定价策 略与商业模式以匹配其战略,实现蓬勃发展。西门子密切关注云化+平台化趋势,开发 Xcelerator 开放式数字商 业平台,构造开放的生态体系,创建功能完善且用户体验良好的 CAD 软件。 海外 CAD 龙头的并购史遵循三类并购逻辑。
- 1)在技术层面进行第一类并购,针对突破核心技术的中小型 公司,获取核心技术,提高竞争壁垒,进一步赋能产品研发。
- 2)在市场层面进行第二类并购,针对具有垂直行 业知识或在某垂直行业取得领先地位的中小型公司,开拓垂直市场,获取对应客群,节省落地成本。
- 3)在生态 层面进行第三类并购,针对生态链条上缺失的 ERP、MSE 等类型软件,完善生态系统,实现应用联动。
CAD 国内领先公司发展态势良好,包括中望软件、浩辰软件、华天软件、数码大方。
- 1)中望软件是领先的 All-in-One CAX 解决方案提供商,2D 领域具有自主内核产品平台 ZWCAD。3D 领域具有自主建模内核 CAX 一 体化软件 ZW3D,产品达到第二阵营技术指标标准,处于国内领先地位,业绩发展良好,教育市场收入不断增 加。
- 2)浩辰软件具有内置协同设计,致力于打造一体化国产 2D CAD 解决方案,同时发展云端,致力于建设国 内领先的云化 CAD 解决方案。2D CAD 为公司主要营收来源,未来看好云化 CAD 业务。
- 3)华天软件具有完全 自主产权,在模具行业处于领先地位,目前公司旗下有 CrownCAD、SINOVATION、Sview、SViewVIZ 等一系 列功能强大的软件产品,营收年化增速达 11.2%,有望继续增长。
- 4)数码大方实现深度产教融合,坚持以“企 业需求为导向,教学实训为中心”。
三、国产算力自主可控
随着大语言模型能力不断升级,生成式 AI 带来个人生产力革命,大语言模型爆发出巨大的应用潜力,模型参数持续提升带来更高的模型训练算力需求,大模型的商业化落地催生了更大的推理算力和通信能力需求。从需求端出发,我们测算了大模型带来的 GPU 增量空间。
测算原理:从模型的(1)参数规模入手,根据(2)训练大模型所需的 Token 数量和(3)每 Token 训练成 本与模型参数量的关系估算总算力需求,再考虑(4)单张 GPU 算力和(5)GPU 集群的算力利用率推导得出 GPU 总需求。
- (1)参数规模:过去几年,大模型的参数量呈指数上升,GPT-3 模型参数量已达到 1750 亿。GPT-4 具有 多模态能力,其参数量相比 GPT-3 会更大。我们在测算中假设 2023 年多模态大模型的平均参数量达到 10000 亿个,之后每年保持 20%的增速;普通大模型的平均参数量达到 2000 亿个,之后每年保持 20%的增速。
- (2)训练大模型所需的 Token 数量:参数规模在千亿量级的自然语言大模型 GPT-3、Jurassic-1、Gopher、 MT-NLG,训练所需的 Token 数量在千亿量级,而一些多模态大模型在训练过程中所需 Token 数据量也跟随参 数量增长而增长,我们在测算中假设多模态大模型训练所需 Token 数量达到万亿级别,并且 Token 数量与模型 参数规模保持线性增长关系。
- (3)每 Token 训练成本与模型参数量的关系:参考 OpenAI 发布的论文《Scaling Laws for Neural Language Models》中的分析,每个 token 的训练成本通常约为 6N,其中 N 是 LLM 的参数数量,我们在测算中遵循这一 关系。
- (4)单张 GPU 算力:因为在训练大模型时,主要依赖可实现的混合精度 FP16/FP32 FLOPS,即 FP16 Tensor Core 的算力,我们在测算中选取 A100 SXM 和 H100 SXM 对应的算力 312 TFLOPS 和 990 TFLOPS 作为参数。
- (5)GPU 集群的算力利用率:参考 Google Research 发布的论文《PaLM: Scaling Language Modeling with Pathways》中的分析,我们在测算中假设算力利用率约为 30%。 其他基本假设包括多模态研发厂商个数、普通大模型研发厂商个数等。根据所有假设及可以得到,2023 年 -2027 年,全球大模型训练端峰值算力需求量的年复合增长率为 78.0%。2023 年全球大模型训练端所需全部算 力换算成的 A100 总量超过 200 万张,新增市场需求空前旺盛。
3.1 国产算力迎来高速发展期
2023 年 10 月 17 日美国商务部和安全局(BIS)发布一揽子规则,旨在更新对中国的先进计算芯片的出口管制。出口管制清单 CCL 中的 ECCN 3A090 修正,该规则将于 2023 年 11 月 16 日起生效。以下条件,满足 一个就受到出口限制: 3A090a:针对最高性能芯片(1): TPP 超过 4800(2): TPP 超过 1600,且 PD 超过 5.92。 3A090b:针对次高性能芯片(1): TPP 处于[2400,4800),且 PD 处于[1.6,5.92);(2): TPP 在[1600,+∞) 区间,且 PD 处于[3.2.5.92)区间。 其中 TPP 为总算力性能,PD 为性能密度,性能密度定义为:总处理性能/芯片面积。
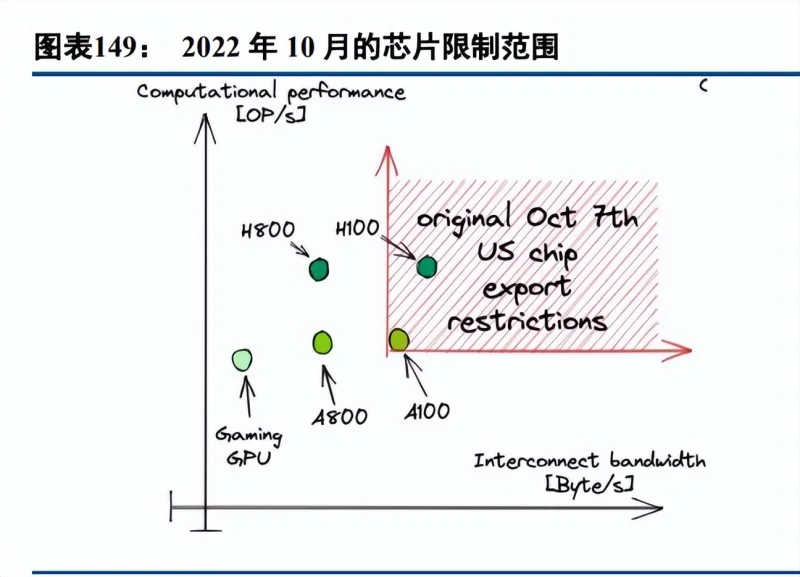
2023 年 10 月 17 日的芯片出口管制禁令更为严格,虽然消除了之前的带宽限制,但是算力限制更为严格。 主流的英伟达 H100、H800、A100、A800、L40S、RTX4090 等均在出口管制范围内。
英伟达和 AMD 是目前全球 GPGPU 的领军企业。英伟达的通用计算芯片具备优秀的硬件设计,通过 CUDA 架构等全栈式软件布局,实现了 GPU 并行计算的通用化,深度挖掘芯片硬件的性能极限,在各类下游应用领域 中,均推出了高性能的软硬件组合,逐步成为全球 AI 芯片领域的主导者。AMD 2018 年发布用于数据中心的 Radeon Instinct GPU 加速芯片,Instinct 系列基于 CDNA 架构,如 MI250X 采用 CDNA2 架构,在通用计算领域 实现计算能力和互联能力的显著提升,此外还推出了对标英伟达 CUDA 生态的 AMD ROCm 开源软件开发平台。 国内 AI 芯片厂商正逐步缩小与英伟达、AMD 的差距,出口管制下国产芯片快速发展势在必行。英伟达凭 借其硬件产品性能的先进性和生态构建的完善性处于市场领导地位,国内厂商虽然在硬件产品性能和产业链生 态架构方面与前者有所差距,但正在逐步完善产品布局和生态构建,不断缩小与行业龙头厂商的差距。国内主 要 AI 芯片包括昇腾、寒武纪、海光信息、天数智芯等。
3.2 服务器:AI 时代全球服务器市场高速增长
3.2.1 AI 时代全球服务器市场高速增长,AI 服务器出货量占比进一步提升
AI 服务器为算力基础设施最重要硬件之一,与普通服务器的绝大多数空间分配给 CPU 相比,AI 服务器 采用异构形式,可根据应用的范围采用不同的组合方式,一般采取 CPU+多颗 GPU 的架构,也有 CPU+TPU、 CPU+其他的加速卡等组合。相较普通服务器,AI 服务器更擅长并行运算,具有高带宽、性能优越、能耗低等优点。对比 CPU 和 GPU 的内部架构,CPU 采用整块的 ALU(运算单元),且大量空间用于控制单元和缓存,串 行计算能力强;而 GPU 采用分立的大量 ALU,很少空间分配给控制单元和缓存,并行计算能力强。而由于图 像识别、视觉效果处理、虚拟现实、大模型训练等任务都包含大量的简单重复计算、矩阵计算等,更适合用搭 载 GPU 更多的异构型 AI 服务器进行处理,而随着企业的智能化变革和通用大模型的兴起,以 GPU 为核心的异 构型 AI 服务器将在算力基础设施建设中占据愈发重要的地位。
IDC 预计,全球 AI 服务器市场将从 2022 年的 195 亿美元增长到 2026 年的 347 亿美元,五年年复合增长率 达 17.3%;其中,用于运行生成式人能的服务器市场规模在整体人工智能服务器市场的占比将从 2023 年的 11.9% 增长至 2026 年的 31.7%。随着数据量的持续提升,大模型参与玩家和单个模型参数量提升,以及数字化转型推 进等多因素影响,AI 服务器市场规模将继续保持较快增长;2022 年中国 AI 服务器市场规模 67 亿美元,同比增 长 24%。其中 GPU 服务器占据主导地位,市场份额为 89%至 60 亿美元。同时,NPU、ASIC 和 FPGA 等非 GPU 加速服务器以同比 12%的增速占有了 11%的市场份额,达到 7 亿美元。预计 2023 年,中国人工智能服务器市场 规模将达 91 亿美元,同比增长 82.5%,2027 年将达到 134 亿美元,五年年复合增长率为 21.8%。
3.2.2 AI 服务器市场集中度有望提升,国内厂商呈现一超多强格局
据 IDC 数据,2022 年上半年全球 AI 服务器市场中,浪潮信息、戴尔、惠普、联想、新华三分别以 15.1%、 14.1%、7.7%、5.6%、4.7%的市场份额位居前五位。市场格局相对分散,龙头厂商份额较为接近。此外,由于以 北美云厂商为主的需求方偏向于采用 ODM 模式,因此非品牌商份额占比较高,接近 50%。 据 IDC 数据,2022 年我国 AI 服务器市场按销售额统计市场份额中,浪潮信息、新华三、宁畅位居前三位, 市场份额分别为 47%、11%、9%。市场格局呈现一超多强局面,除浪潮外其与厂商份额相对接近。由于国内头 部厂商采用类 ODM 模式服务互联网客户,因此 ODM 厂商份额占比偏低。
四、大模型技术基座国产化
4.1 EDA 算法国产替代
EDA 板块:增速稳定、高壁垒、高估值板块。
1)增速稳定:EDA 公司商业模式大多数为按年付费,一般 收费在 IC 设计公司收入的 1%-3%之间,占 IC 公司收入比重较低,并且 EDA 公司议价权较高,因此对于成熟 稳定的客户,每年给 EDA 公司付费基本稳定或者略有增长,商业模式和高壁垒决定了 EDA 公司受下游需求波 动影响较小。EDA 行业增长一是受益于 IC 设计门槛降低,IC 公司数量越来越多,二是 IC 品类不断拓张,比如 第三代半导体的出现,三是伴随着先进制程迭代,产品复杂度提高带来的单价提升。加上盗版等因素的存在, 实际上有部分需求并未体现在 EDA 公司收入中,通过盗版的不断转化,EDA 龙头公司中长期均保持稳定增长。
2)高壁垒;技术壁垒本身较高,需要强大的数学物理基础理论支撑,对算法要求很高。同时用户协同壁垒较高, 制造、设计、EDA 厂商三方形成稳定的生态圈,新进入者极难打破。因此,高壁垒以及良好的业务稳定性和成 长性,使得 EDA 公司如新思科技、Cadence 在美股半导体板块中估值一直相对较高。
EDA 行业保持稳定增长,国内增速更快。根据赛迪数据,2020 年全球 EDA 行业实现总销售额 72.3 亿美元, 同比增长 10.7%。预计至 2024 年,全球市场规模有望达到 105 亿美元,2020-2024 年复合年均增长率为 7.8%。 2020 年国内 EDA 市场规模为 66.2 亿,预计至 2024 年,我国 EDA 工具市场规模有望达到 115 亿元人民币,2020 至 2024 年的市场规模符合年均增长率近 17%。
EDA 结合人工智能是趋势。EDA 问题具有高维度、不连续、非线性和高阶交互的特性,机器学习等算法 能够显著提高 EDA 的自主程度,提升 IC 设计效率,缩短研发周期。人工智能赋能 EDA 主要从 Inside 和 Outside 两方面实现,从 Inside 方面,通过机器学习对 DRC、能耗、时序等预测,在参数模型建立过程中实现参数的优 化,同时实现更高效的物理空间设计。Outside 方面,通过机器学习方式,减少人工干预,极大释放劳动力。
EDA巨头积极进行人工智能与芯片设计的深度融合。EDA巨头Cadence发布了内嵌人工智能算法的Innovus, Project Virtus,Signoff Timing 等工具,实现了全流程数字化智能化。Mentor 通过机器学习 OPC 将光学邻近效应 修正(OPC)输出预测精度提升到纳米级,同时将执行时间缩短 3 倍。Synopsys 推出业界首个用于芯片设计的自 主人工智能应用程序——DSO.aiTM。英伟达发布大语言模型 ChipNeMo,辅助工作人员完成与芯片设计相关的 任务,可以回答有关芯片设计的一般问题、总结 bug 文档,以及为 EDA 工具编写脚本等。 国产 EDA 产商迎来新战略机遇期。目前全球 EDA 工具上大约有近百家,排名前三的公司分别是新思科技 (Synopsys)、铿腾电子(cadence)和明导(Mentor),三家巨头占据着全球近 7 成左右的市场份额,在中国的 市占率更是超过 95%。2022 年 8 月生效的《2022 芯片与科学法案》对 EDA 软件进行了出口管制,在中美贸易 战、科技战持续深化的背景下,加强对卡脖子的关键核心技术研发的支持成为半导体领域的重点,半导体芯片的软硬件国产化比例不断提升,芯片核心技术自主可控势在必行,国产 EDA 厂商迎来重要的发展机遇。
完整报告详见:人工智能行业深度报告:AI下半场,应用落地,赋能百业.pdf - 文档下载 - 未来智库 (vzkoo.com)

