一、选题背景
随着航天技术的快速发展,空间活动任务类型呈现出多元化的发展趋势。其中,太空垃圾快速清除、故障卫星在轨维修、空间目标监视寄生、空间卫星交会对接等任务成为了航天领域的研究热点。在执行空间任务过程中,需要实时感知目标三维结构,进一步基于目标三维结构解算目标位姿、部件位置等信息,最终完成空间在轨特定任务。可以说,能否精确获取空间非合作目标三维精细结构直接决定了诸多空间在轨任务能否顺利完成,因此迫切需要开展空间目标三维结构感知技术研究。
目前,可通过不同探测手段获取空间非合作目标三维结构,依据所需传感器的不同可分为基于双目视觉的目标结构重建方法与基于深度相机的目标结构测量方法。其中,基于双目视觉的目标结构重建方法利用三角测量原理实现目标特征点空间位置估计。但该方法较为依赖提取的目标特征点,对表面光滑/纹理单一的目标效果较差。此外,受基线长度的限制,基于双目视觉的目标结构重建系统工作距离较短(≤20m)。而基于深度相机的目标结构测量方法基于主动成像方式获取目标三维精细结构,但该类方法功耗较高,且工作距离一般小于10m。
针对当前目标三维结构感知方法存在的缺陷,本作品旨在突破传统方法对系统工作距离、目标材质、光照条件等因素的限制,提出了采用可见光相机与激光雷达协同探测方案实现远距离目标(≤250m)三维结构感知,并设计开发多传感器数据融合算法实现目标三维精细结构智能重建,该技术能够为空间在轨任务提供重要的技术支持。
二、作品内容
面向空间目标三维结构感知任务需求,深入开展基于可见光图像与激光雷达数据融合的空间目标三维精细结构智能建模技术研究。通过前景区域分割、多源数据特征提取、异源特征融合、目标深度回归等步骤,实现空间目标三维精细结构智能重建。该技术突破了传统目标三维结构感知方法工作距离的限制,能够为空间在轨任务提供重要的技术支持。
三、作品主要创新点
(1)针对传统空间目标三维结构感知方法存在的工作距离近、材质敏感等缺陷,作品提出了基于单目视觉相机与激光雷达协同探测的空间目标三维结构测量方案,并设计开发了基于可见光图像与稀疏深度数据的空间目标三维精细结构智能重建算法,有效提升了空间目标三维结构测量系统工作距离。
(2)针对星空背景干扰导致目标三维结构重建结果精度较低的问题,作品提出将空间目标三维结构重建任务分解为前景目标分割子任务与前景目标深度估计子任务。通过设计轻量化网络实现航天器前景区域分割,进一步对分割区域像素进行深度预测与回归,使得网络能够集中于恢复前景目标深度,从而获得更为精确的深度预测结果。
(3)为了充分利用灰度图像与稀疏深度图像间互补信息,作品提出了一种基于注意力的异源特征融合模块完成不同传感器数据特征深度融合。通过挖掘异源特征在通道维度与空间维度关联关系推断特征间交叉通道注意力图与空间注意力图,进而依据推断结果聚合异源特征信息,为空间目标三维精细结构恢复提供重要线索与依据。
(4)作品提出了四种新型三维结构恢复精度评价指标用于评价目标级几何结构恢复精度,其中兴趣区域平均绝对误差(MAEI)与兴趣区域均方根误差(RMSEI)直观地反应了三维结构重建算法对有效前景区域深度回归误差,而截断平均绝对误差(MATE)与截断均方根误差(RMSTE)使用截断误差评估预测前景区域深度回归误差,能够综合评估目标整体结构恢复精度。
四、技术方案
本作品设计的空间目标三维结构重建网络总体框架如下所示。该网络主要由前景分割子网络(Foreground Segmentation Network, FSNet)与前景深度补全子网络(Foreground Depth Completion Network, FDCNet)组成。其中前景分割子网络采用编码-解码网络结构预测各像素属于前景目标的概率,从而实现前景区域分割。在此基础上,前景深度补全子网络借助异源特征融合模块完成不同传感器数据特征深度融合,进一步对预测的前景区域进行深度回归实现空间目标深度补全,最终生成高质量目标三维结构。
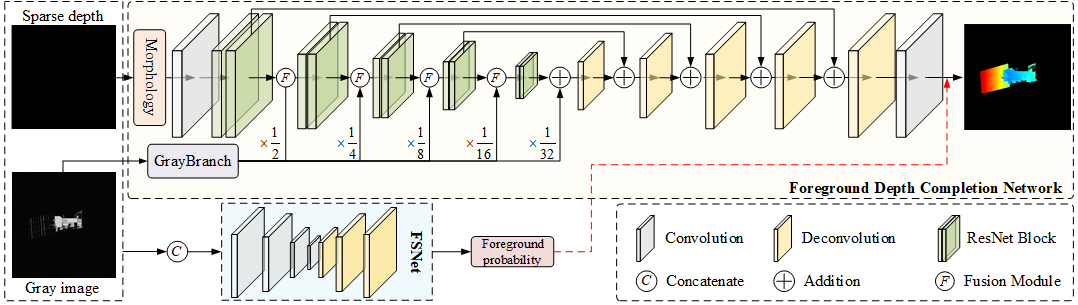
1、前景分割子网络
由于空间目标在轨图像往往仅包含航天器目标与星空背景,场景深度恢复任务可以看作目标级深度补全任务。此时,若直接对图像场景中所有像素进行深度回归,不仅会由于前背景样本数量失衡导致网络性能下降,同时会使得网络更趋向于学习使整体图像深度误差最小(包含前景与背景)而非使目标深度误差最小的权重参数。为此,本作品设计了一个轻量化的前景分割子网络用于航天器前景区域分割。该子网络核心代码如下:
# 定义反卷积模块
class Basic2dTrans(nn.Layer):
def __init__(self, in_channels, out_channels, norm_layer=None, weightattr=None):
super().__init__()
self.conv = nn.Conv2DTranspose(in_channels=in_channels, out_channels=out_channels, kernel_size=3,
stride=2, padding=1, output_padding=1, bias_attr=False, weight_attr=weightattr)
if norm_layer is not None:
self.bn = norm_layer(out_channels)
else:
self.bn = None
self.relu = nn.ReLU()
def forward(self, x):
out = self.conv(x)
if self.bn is not None:
out = self.bn(out)
out = self.relu(out)
return out
# FSNet网络结构
class FSNet(nn.Layer):
def __init__(self, weightattr=None):
super(FSNet, self).__init__()
self.conv_img = Basic2d(2, 16, norm_layer=nn.BatchNorm2D, kernel_size=5, padding=2, weightattr=weightattr)
self.encoder1 = nn.Sequential(
nn.Conv2D(16, 16, kernel_size=3, stride=2, padding=1, weight_attr=weightattr),
nn.BatchNorm2D(16),
nn.ReLU())
self.encoder2 = nn.Sequential(
nn.Conv2D(16, 32, kernel_size=3, stride=2, padding=1, weight_attr=weightattr),
nn.BatchNorm2D(32),
nn.ReLU())
self.encoder3 = nn.Sequential(
nn.Conv2D(32, 64, kernel_size=3, stride=2, padding=1, weight_attr=weightattr),
nn.BatchNorm2D(64),
nn.ReLU())
self.decoder1 = Basic2dTrans(64, 32, nn.BatchNorm2D, weightattr=weightattr)
self.decoder2 = Basic2dTrans(32, 16, nn.BatchNorm2D, weightattr=weightattr)
self.decoder3 = Basic2dTrans(16, 16, nn.BatchNorm2D, weightattr=weightattr)
self.head = nn.Sequential(nn.Conv2D(16, 1, kernel_size=3, padding=1, stride=1, weight_attr=weightattr),
nn.Sigmoid())
if weightattr is None:
self._initialize_weights()
def forward(self, rgb, lidar):
#rgb: 灰度图像,[B, 1, 512, 512]
#lidar: 稀疏深度图像, [B, 1, 512, 512]
temp = paddle.concat([rgb, lidar], axis=1)
c0_img = self.conv_img(temp)
c1_img = self.encoder1(c0_img)
c2_img = self.encoder2(c1_img)
c3_img = self.encoder3(c2_img)
dc3img = self.decoder1(c3_img)
dc2_img = self.decoder2(dc3img + c2_img)
dc1_img = self.decoder3(dc2_img + c1_img)
fs_pred = self.head(dc1_img)
return fs_pred2、前景深度补全子网络
前景深度补全子网络主要由灰度图像特征提取分支与深度图像补全分支组成,其中灰度图像特征提取分支旨在提取目标几何结构与语义特征,用于对深度图像补全分支中目标深度补全任务提供指导。而深度图像补全分支旨在提取目标三维深度特征完成目标深度恢复。在深度图像补全分支中,本作品设计了异源特征融合模块实现灰度特征与深度特征的深度融合,从而获得富含目标结构、纹理、语义、深度等信息的特征表征,进一步基于融合特征对目标稠密深度进行预测,最终实现目标三维精细结构的智能重建。
在网络结构设计方面,可见光图像分支与深度图像分支均采用带有跳跃连接的编码-解码网络结构。作品采用resnet-18作为灰度图像特征提取分支的编码网络,并进一步利用反卷积操作与跳跃连接实现目标特征解码,生成具有不同空间分辨率的灰度图像特征。这些特征将对目标稠密深度预测提供重要的几何结构与语义信息。深度图像分支网络总体结构与可见光图像分支网络相同,但在深度图像编码网络的不同阶段嵌入异源特征融合模块对可见光特征与深度特征进行融合(如网络总体结构所示)。
在目标几何结构恢复过程中,如何充分利用灰度图像与雷达深度图像间的互补信息,完成异源特征融合目前仍是一个开放性问题。考虑到灰度图像中富含目标几何结构、纹理特征以及语义信息,而深度图像特征主要包含目标三维结构特征,为了更好的融合异源特征,作品将异源特征融合分为两个阶段:空间不变的交叉通道融合阶段以及空间可变的通道平行融合阶段,具体结构如下图所示。异源特征融合模块主要由特征嵌入层、交叉通道注意力层以及空间注意力层组成。其中特征嵌入层对不同通道特征图进行编码,并生成相应的特征向量;交叉通道注意力层利用多头注意力机制计算不同特征通道间注意力权重,并进一步基于通道权重实现特征间交叉通道融合;而空间注意力层综合利用深度特征与可见光特征的空间信息,计算不同空间位置下不同特征的重要性,从而实现空间可变的同通道特征融合。
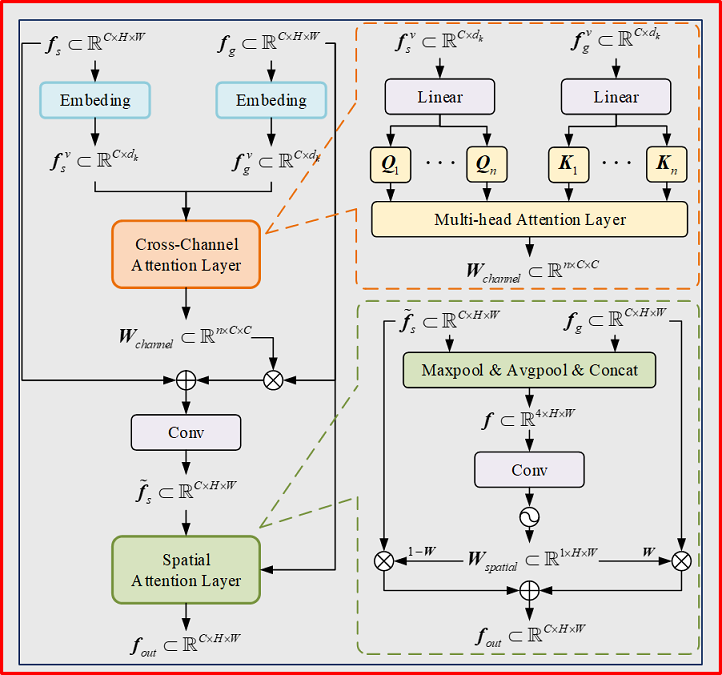
异源特征融合模块核心代码如下:
class SpatialAttentation(nn.Layer):
def __init__(self):
super(SpatialAttentation, self).__init__()
self.conv = nn.Conv2D(4, 2, kernel_size=3, stride=1, padding=1, bias_attr=False)
def forward(self, input, weight):
"""
:param input: 灰度图像特征图, [B, C, H, W]
:param weight: 深度图像特征图, [B, C, H, W]
:return: out: 增强特征, [B, C, H, W]
"""
input_avg = paddle.mean(input, axis=1, keepdim=True)
input_max = paddle.max(input, axis=1, keepdim=True)
weight_avg = paddle.mean(weight, axis=1, keepdim=True)
weight_max = paddle.max(weight, axis=1, keepdim=True)
attn = paddle.concat([input_avg, input_max, weight_avg, weight_max], axis=1) # [B, 4, H, W]
attn = self.conv(attn) # [B, 2, H, W]
attn = F.softmax(attn, axis=1)
out = input * attn[:, 0:1, ::] + weight * attn[:, 1:2, ::]
return out
class FeatureFusionModule(nn.Layer):
def __init__(self, input_shape, patch_size, num_heads, dropout=0.0):
"""
:param input_shape: 输入特征图尺寸
:param patch_size: 区域块尺寸
:param num_heads: 注意力头数
:param dropout:
"""
super(FeatureFusionModule, self).__init__()
C, H, W = input_shape
assert H % patch_size == 0
assert W % patch_size == 0
assert (H * W / patch_size ** 2) % num_heads == 0
self.patch_size = patch_size
self.num_heads = num_heads
self.dropout = dropout
# 特征嵌入层:沿着通道维度将特征图转换为特征向量
self.embed1 = nn.Conv2D(C, C, kernel_size=patch_size, stride=patch_size, padding=0,
groups=C, bias_attr=False)
self.embed2 = nn.Conv2D(C, C, kernel_size=patch_size, stride=patch_size, padding=0,
groups=C, bias_attr=False)
self.embed_max = nn.AdaptiveMaxPool2D(output_size=(H // patch_size))
self.embed_avg = nn.AdaptiveAvgPool2D(output_size=(H // patch_size))
# feed forward(MLP)
self.ff1 = FeedForward((3 * H * W // patch_size ** 2), ratio=4, dropout=dropout)
self.ff2 = FeedForward((3 * H * W // patch_size ** 2), ratio=4, dropout=dropout)
# 基于线性变换获得Q、K、V
self.mha1 = nn.Conv1D((H * W // patch_size ** 2), (H * W // patch_size ** 2), kernel_size=1, bias_attr=False,
data_format="NLC")
self.mha2 = nn.Conv1D((H * W // patch_size ** 2), (H * W // patch_size ** 2), kernel_size=1, bias_attr=False,
data_format="NLC")
# 对多头注意力输出进行卷积
self.mha_conv = nn.Conv2D(C * num_heads, C, kernel_size=3, padding=1, groups=C)
self.br = nn.Sequential(
nn.BatchNorm2D(C),
nn.ReLU()
)
self.sa = SpatialAttentation()
def forward(self, input, weight):
"""
:param input: 灰度图像特征图, [B, C, H, W]
:param weight: 深度图像特征图, [B, C, H, W]
:return: out: 增强特征, [B, C, H, W]
"""
B, C, H, W = input.shape
# 特征嵌入层
input_embed1 = paddle.reshape(self.embed1(input), [B, C, -1]) # [B, C, H*W/S**2]
input_embed2 = paddle.reshape(self.embed_max(input), [B, C, -1]) # [B, C, H*W/S**2]
input_embed3 = paddle.reshape(self.embed_avg(input), [B, C, -1]) # [B, C, H*W/S**2]
input_embed = paddle.concat([input_embed1, input_embed2, input_embed3], axis=-1) # [B, C, 3*H*W/S**2]
weight_embed1 = paddle.reshape(self.embed2(weight), [B, C, -1]) # [B, C, H*W/S**2]
weight_embed2 = paddle.reshape(self.embed_max(weight), [B, C, -1]) # [B, C, H*W/S**2]
weight_embed3 = paddle.reshape(self.embed_avg(weight), [B, C, -1]) # [B, C, H*W/S**2]
weight_embed = paddle.concat([weight_embed1, weight_embed2, weight_embed3], axis=-1) # [B, C, 3*H*W/S**2]
# 交叉通道注意力层
## feed forward (MLP)
input_embed = self.ff1(input_embed) # [B, C, H*W/S**2]
weight_embed = self.ff2(weight_embed) # [B, C, H*W/S**2]
## 利用线性变换求取Query、Key、Value
Q1 = self.mha1(input_embed) # [B, C, H*W/S**2]
Q1 = paddle.transpose(paddle.reshape(Q1, [B, C, self.num_heads, -1]), perm=[0, 2, 1, 3]) # [B, n_head, C, H*W/S**2/n_head]
K2 = self.mha2(weight_embed) # [B, C, H*W/S**2]
K2 = paddle.transpose(paddle.reshape(K2, [B, C, self.num_heads, -1]), perm=[0, 2, 1, 3]) # [B, n_head, C, H*W/S**2/n_head]
## 计算交叉通道注意力图
scores = paddle.matmul(Q1, paddle.transpose(K2, perm=[0, 1, 3, 2])) / math.sqrt(Q1.shape[-1]) # [B, n_head, C, C]
scores = F.softmax(scores, axis=-1) # 交叉通道注意力图,[B, n_head, C, C]
## 加权求和
weight_flatten = paddle.reshape(weight, [B, C, -1]).unsqueeze(1) # [B, C, H*W]
weight_flatten = paddle.tile(weight_flatten, [1, self.num_heads, 1, 1]) # [B, n_head, C, H*W]
weight_flatten = paddle.matmul(scores, weight_flatten) # [B, n_head, C, H*W]
weight_flatten = paddle.reshape(weight_flatten, [B, self.num_heads, C, H, W])
weight_flatten = paddle.reshape(paddle.transpose(weight_flatten, perm=[0, 2, 1, 3, 4]), [B, self.num_heads * C, H, W])
weight_flatten = self.mha_conv(weight_flatten) # [B, C, H, W]
out = self.br(input + weight_flatten)
## 空间注意力层
out = self.sa(out, weight)
return out五、数据集构建
为了构建卫星深度补全数据集,团队购买了126个卫星CAD模型,并利用blender软件对空间目标进行可见光成像仿真与激光雷达成像仿真,最终获得了6336组训练样本、576组验证样本以及1152组测试样本。

六、作品效果展示
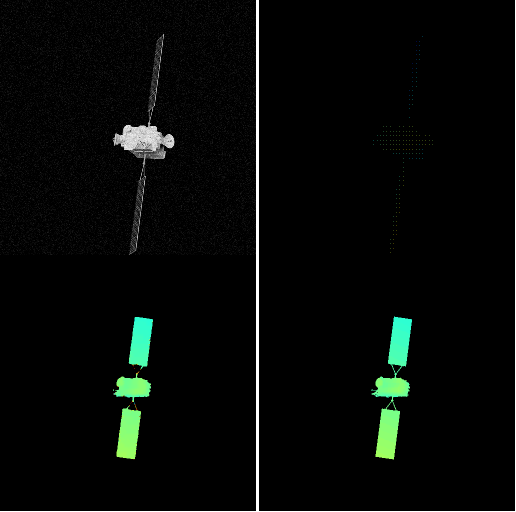
下列动画依次展示了目标灰度图像、稀疏雷达图像、网络预测深度图像与目标深度图像地面标签可视化结果。可以看出,作品所提方法能够精确预测目标深度图像,从而完成目标三维结构恢复。.


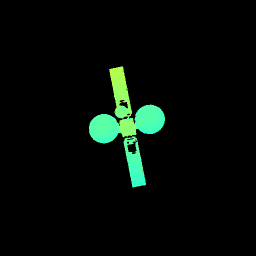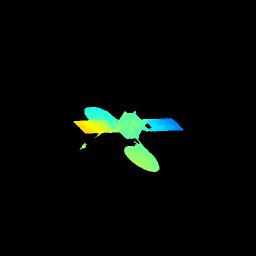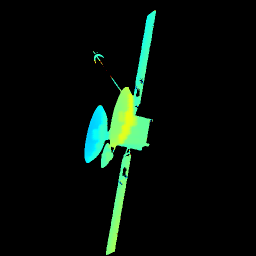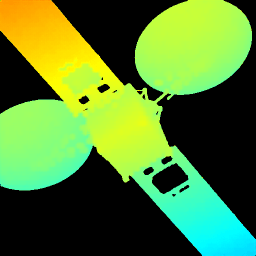
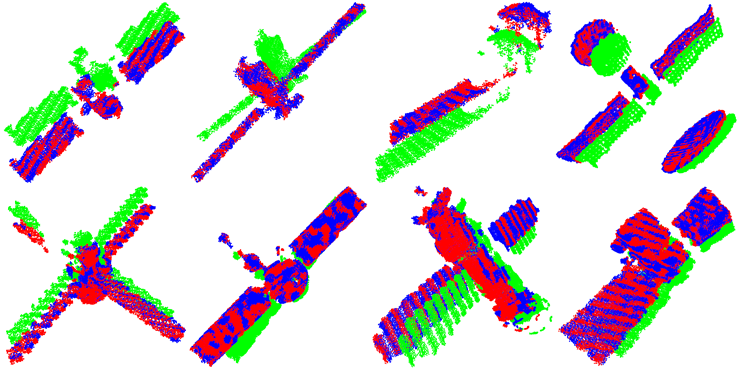
七、下游任务应用
为了评估空间目标三维结构重建质量,验证其能否满足下游视觉任务需要,作品将重建结果作为航天器位姿测量算法输入(作品选用航天器位姿测量算法PANet作为测试算法),位姿测量可视化结果如下图所示。其中绿色点云、蓝色点云与红色点云分别代表参考点云(前一帧点云数据)、目标点云(当前帧点云数据)以及经位姿变换后的参考点云数据。可以看出,变换后的参考点云与目标点云重合程度较高,说明位姿测量结果具有较高的精度。该实验验证了作品恢复的目标三维结构能够满足下游视觉任务应用需求。